Auteur : Paul Passy
Licence : 
Travailler sur les tables attributaires
Comme vu dans la partie de présentation des différents formats de données, les données vecteurs sont caractérisées par la présence d’une table attributaire. Ces tables attributaires sont ds éléments primordiaux des SIG. Cette partie présente quelques manipulations à savoir faire sur ces tables. Ces manipulations vont du calcul de champ à la mise à jour d’un champ en passant par la suppression ou le formatage d’un champ (et autres).
Table des matières
Exploration des attributs
Une fois une couche vecteur chargée dans son logiciel de SIG préféré ou dans son script, il est souvent utile d’en faire une exploration basique : lister les champs, calculer des statistiques sur les champs, … Nous explorerons ici les attributs d’une couche vecteur contenant les polygones des communes d’Île-de-France communes_IDF.gpkg.
Exploration des attributs dans QGIS
Version de QGIS : 3.22.3
Dans QGIS, pour ouvrir la table attributaire associée à une couche vecteur il suffit de faire un clic droit sur la couche dans le panneau de couches et de sélectionner Ouvrir la Table d'Attributs (Fig. 200).
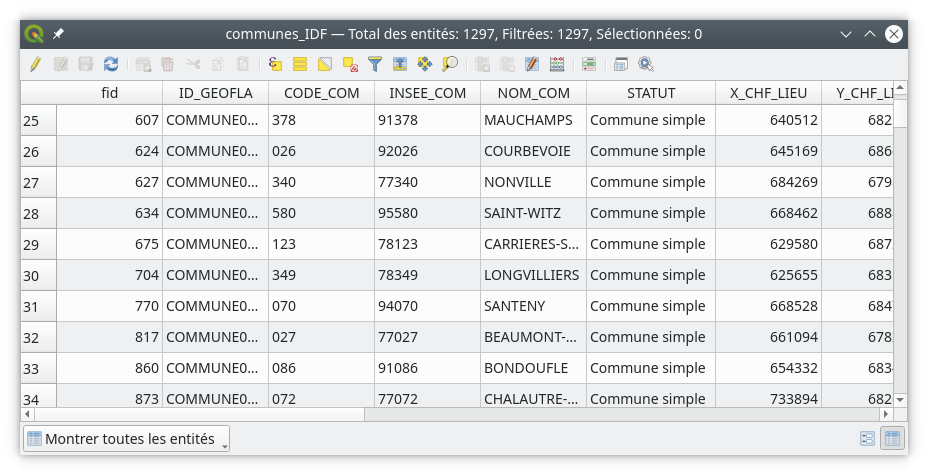
Fig. 200 Une table attributaire ouverte dans QGIS.
Chaque colonne correspond à un attribut aussi appelé champ et chaque ligne correspond à une entité. Si nous souhaitons maintenant avoir une vue plus simple à lire de la liste des champs ainsi que du format de chacun des champs, il suffit de faire un clic droit sur la couche dans le panneau des couches puis de sélectionner . Nous trouvons dans cette fenêtre la liste de tous les champs avec leurs caractéristiques (Fig. 201).
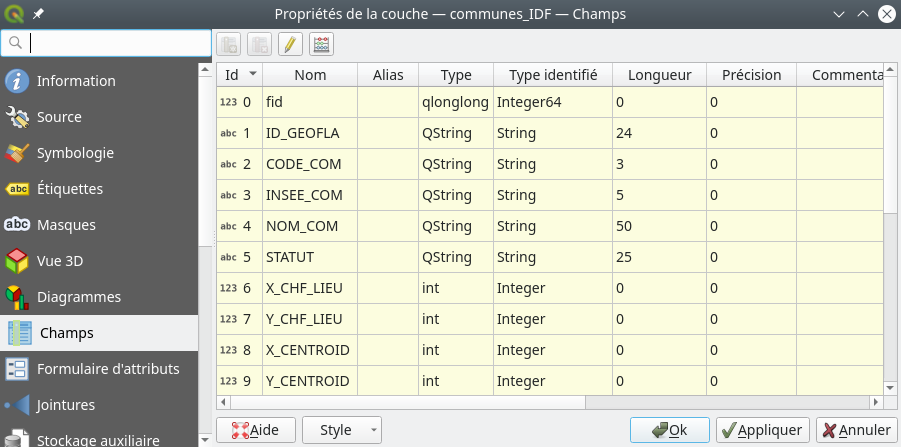
Fig. 201 Caractéristiques des champs d’une table attributaire dans QGIS.
Il est également possible d’explorer des statistiques basiques sur chacun des champs, comme la moyenne ou les valeurs extrêmes pour les champs numériques. Dans QGIS, cela se fait simplement en allant dans le menu (Fig. 202).
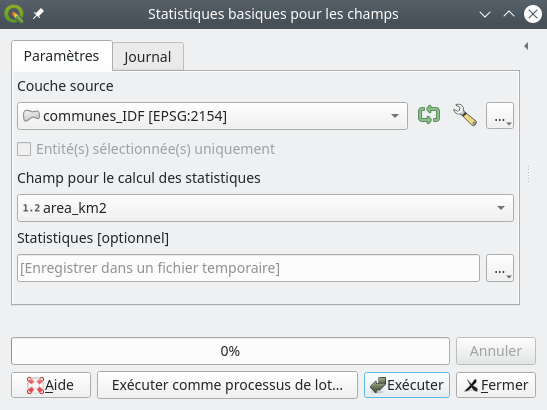
Fig. 202 Statistiques basiques sur les champs dans QGIS.
Dans la fenêtre du menu, dans le champ Couche source nous indiquons la couche à analyser, ici communes_IDF puis dans le champ Champ pour le calcul des statistiques, nous indiquons le champ sur lequel calculer les statistiques, ici par exemple area_km2. Dans le champ Statistiques nous pouvons sauver le résultat dans un fichier HTML si nous le souhaitons. Mais la sortie standard est souvent suffisante. Puis nous cliquons sur Exécuter. Les statistiques apparaissent alors sous forme de texte (un peu brut certes) dans l’onglet Journal de la fenêtre.
Il existe un autre moyen d’accéder à ces statistiques basiques qui est peut-être plus facile à lire. Il suffit d’ajouter le panneau Statistiques à la vue générale de QGIS. Pour cela nous allons dans le menu . Un nouveau panneau apparaît alors sous le panneau Couches (Fig. 203).
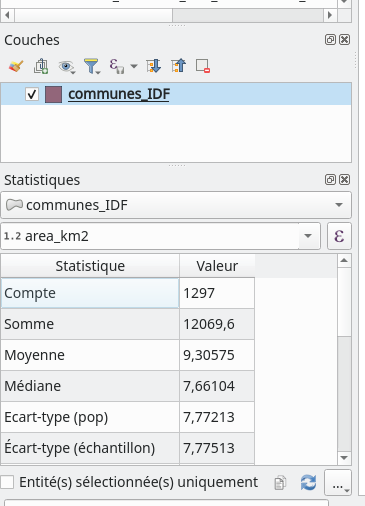
Fig. 203 Le panneau statistiques dans QGIS.
Dans ce panneau nous commençons par sélectionner la couche à analyser dans le premier menu déroulant puis le champ sur lequel calculer les statistiques dans le second menu déroulant. Les statistiques apparaissent alors dans une liste plus lisible que précédemment.
Astuce
Nous pouvons même calculer les statistiques seulement sur les entités respectant une certaine condition en cliquant sur l’icône de requête  qui se trouve juste à droite du menu déroulant pointant vers le champ à analyser.
qui se trouve juste à droite du menu déroulant pointant vers le champ à analyser.
Calcul de champs
Les tables attributaires associées aux données vecteurs sont des objets fondamentaux en géomatique. Ces objets sont sans cesse modifier au cours du travail. Dans cette section nous allons voir comment mettre à jour une table attributaire en ajoutant un nouveau champ et en mettant à jour ce champ selon un calcul défini par l’utilisateur.
Calcul de champs dans QGIS
Version de QGIS : 3.16.1
Dans QGIS, la mise à jour d’un champ est assez simple et passe par la Calculatrice de champ. Un champ peut être mis à jour avec une valeur unique, en fonction de valeurs contenues dans d’autres champs (comme un calcul de densité de population à partir de champs « population » et « superficie » préexistants) ou en fonction de la géométrie de chaque entité (comme un calcul de superficies, périmètres …)
Dans cet exemple, nous allons simplement calculer la superficie en kilomètres carrés de chaque bassin-versant unitaire du bassin de la Seine. Nous travaillerons sur la couche nommée hydro_bv_seine.
Une fois la couche chargée dans QGIS, nous sélectionnons notre couche dans le panneau des couches et nous ouvrons la Calculatrice de champ en cliquant sur l’icône  . Le menu correspondant apparaît (Fig. 204).
. Le menu correspondant apparaît (Fig. 204).

Fig. 204 Calcul d’un nouveau champ avec QGIS.
Nous spécifions tout d’abord que nous créons un nouveau champ en sélectionnant Créer un nouveau champ. Notons qu’il serait également possible de mettre à jour un champ existant en sélectionnant Mise à jour d'un champ existant. Dans le champ Nom, nous baptisons notre champ superficie_km2.
Note
Il est bien d’inclure l’unité dans le nom des champs.
Dans le champ Type, nous spécifions le type du champ que nous allons créer. Ici, il s’agît d’une superficie, qui sera un nombre décimal. Nous sélectionnons donc Nombre décimal (réel).
Note
Les différents types possibles dépendent du format du fichier que nous mettons à jour. Un GeoPackage accepte plus de formats différents qu’un shapefile par exemple.
Dans le panneau Expression, nous allons entrer l’expression à utiliser pour le calcul du champ. Cette expression peut être écrite avec l’aide des fonctions données dans le panneau central. Pour la superficie, dans ce panneau central, nous déroulons le menu Géométrie et nous doubles cliquons sur $area. Cette expression apparaît dans le panneau Expression. Comme notre couche est en Lambert 93 dont l’unité est le mètre, il nous faut diviser la superficie par 1000000 pour obtenir une superficie en kilomètres carrés. Nous obtenons ainsi l’expression $area / 1000000.
Astuce
Dans la majorité des cas, nous utilisons la fontion $area, mais il existe aussi une fonction area. Quelle est la différence entre les deux ? Dans le premier cas, la surface est calculée en prenant en compte l’ellipsoïde du SCR. Autrement dit, il s’agît d’une surface qui prend en compte la courbure de la Terre. Dans le second cas, la surface est calculée de façon planimétrique, comme si la Terre était plate. C’est pourquoi, nous utilisons le plus souvent la fonction $area qui donne des résultats plus proches de la réalité.
Une fois l’expression entrée, nous cliquons sur OK. Nous avons bien maintenant un champ de superficie associée à la table attributaire (Fig. 205).
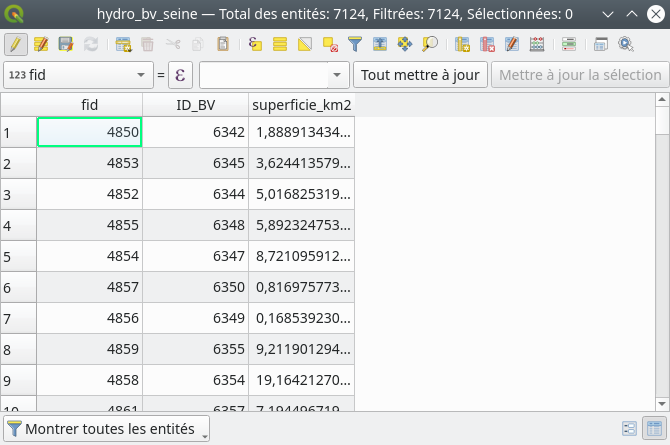
Fig. 205 Le champ de superficie en kilomètres carrés.
Notons qu’au moment du calcul du champ, la couche passe automatiquement en mode édition. Il est ensuite nécessaire d’enregistrer la modification en cliquant sur l’icône Enregistrer les modifications de la couche  puis de quitter le mode édition en cliquant sur l’icône Basculer en mode édition
puis de quitter le mode édition en cliquant sur l’icône Basculer en mode édition  .
.
Astuce
Dans la Calculatrice de champ, dans le panneau central nous trouvons le menu déroulant Récent (fieldcalc) qui contient l’historique des dernières expressions calculées. Ce menu s’avère très pratique à l’usage.
Calcul de champs dans R
Version de R : 4.8.1
Après l’import d’un fichier vecteur dans R, il est possible de manipuler ses attributs et notamment d’en calculer de nouveaux. Ici, nous travaillerons sur un vecteur des départements de France métropolitaine de type polygone, stocké dans une variable nommé dep sous forme d’un objet sf. Cette couche est projetée en Lambert 93 (Pour la France).
Ajout d’un champ texte
Nous pouvons ajouter à chaque entité un attribut de type texte nommé type_admin qui contiendra simplement le terme departement. Cette manipulation se fait suivant la syntaxe classique de R.
dep$type_admin <- 'departement'
Par cette simple commande, un nouveau champ nommé type_admin sera ajouté et rempli selon la valeur désirée.
Astuce
Cette manipulation est valable aussi bien pour les objets sf que SpatVector.
Ajout d’un champ lié à la géométrie
Nous pouvons ajouter un champ lié à la géométrie de la couche, comme une superficie, une longueur, un couple (X, Y), … Ces valeurs seront exprimées dans l’unité du système de coordonnées de référence de la couche. Il s’agît dans la plupart des cas de mètres, mais attention il peut également s’agir de degrés dans le cas des SCR globaux (Pour le monde). Ici, nous allons ajouter un attribut, nommé superficie, qui stockera la superficie de chaque département exprimée en kilomètres carrés. Comme cette couche est en Lambert 93, son unité de base est le mètre. Il faudra bien penser à faire la conversion des m2 vers les km2.
Calcul-champ-geom avec terra
Version de R : 4.3.1
Version de terra : 1.7.29
Avec un objet SpatVector, la fonction de calcul de la superficie est expanse, et celle du calcul du périmètre est perim. En plus de la superficie, nous allons également calculer le périmètre de chaque département en km.
# chargement du vecteur
dep <- terra::vect('departements_france_L93.gpkg')
# ajout d'une colonne de superficie
dep$superficie_km2 <- terra::expanse(dep) / 1000000
# ajout d'une colonne de périmètre
dep$perimetre_km <- terra::perim(dep) / 1000
Calcul-champ-geom avec sf
Version de R : 4.3.1
Version de sf : 1.0.12
La librairie sf utilisée est st_area(). Cette méthode renvoie la superficie de chacune des entités de la couche dans l’unité de référence de la couche. Nous divisons cette valeur par 1000000 afin de passer des superficies en m2 vers des superficies en km2.
dep$superficie <- as.numeric(st_area(dep) / 1000000)
Astuce
Nous convertissons ce nouvel attribut en numérique via la méthode as.numeric(). Si nous le le faisons pas, le champ ne sera pas de type numérique mais dans un type nommé units qui sera moins facile à manipuler.
Ajout d’un champ d’ID
Il peut être utile d’ajouter un champ ID qui contiendra un identifiant unique pour chaque entité d’une couche vecteur donnée. Ici, nous ajouterons un champ ID à une couche de départements.
Ajout d’un champ d’ID avec terra
Version de R : 4.3.1
Version de terra : 1.7.29
# import de la couche à utiliser
dep <- terra::vect('departements_france_L93.gpkg')
# ajout d'une colonne d'ID
dep[['ID']] <- 1:nrow(dep)
Nous avons ajouté à notre SpatVector une colonne ID contenant un identifiant unique.
Ajout d’un champ d’ID avec sf
Version de R : 4.3.1
Version de sf : 1.0.12
# import de la couche à utiliser
dep <- sf::st_read('departements_france_L93.gpkg')
# ajout d'une colonne d'ID
dep_id <- cbind(ID = 1:nrow(dep), dep)
Nous avons créé une nouvelle couche dep6 dans laquelle une colonne d’ID a été ajoutée. Les numéros d’ID sont dans l’ordre d’enregistrement des entités.
Renommer un champ
Les tables attributaires associées aux données vecteurs ne sont pas figées. L’utilisateur peut tout à fait renommer un champ pour rendre son intitulé plus explicite ou corriger une faute de frappe.
Renommer un champ dans QGIS
Version de QGIS : 3.16.1
La manipulation est simple, mais le chemin pour le faire ne se devine pas. Une fois la couche à modifier chargée dans QGIS, nous allons dans ses Propriétés en cliquant droit sur la couche en question dans le panneau des couches et en sélectionnant le menu Propriétés. Une fois les propriétés ouvertes nous allons dans l’onglet Champs (Fig. 206).
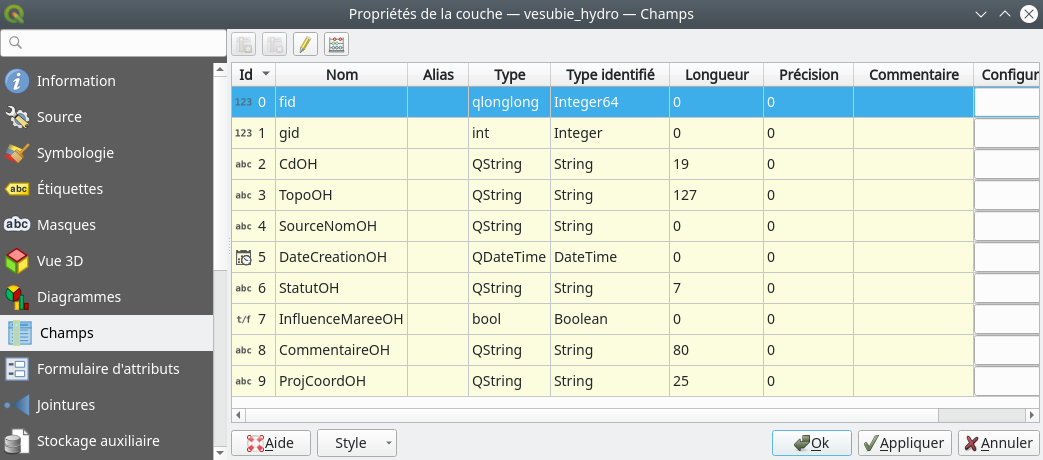
Fig. 206 Les propriétés des champs d’une couche vecteur.
Nous y trouvons la liste des champs de la couche vecteur. Nous trouvons notamment le Nom des champs qui est l’intitulé des champs. Il y a également le Type des champs. Ici, nous avons des champs de type QString, Int et même QDateTime. Dans la colonne d’à côté, nous avons le nom générique de ces types : String (texte), Integer (entier) et DateTime (date avec l’heure). Nous avons également la Longueur et la Précision des champs. Par exemple, le champ CdOH contient du texte qui ne peut pas contenir plus de 19 caractères.
Le nombre de types de champs possibles varient selon le format du fichier. Ici, il s’agît d’un GeoPackage, format qui propose une certaine variété de types possibles. Par contre, un shapefile sera plus limité. Le type DateTime ne sera, par exemple, pas possible dans ce format.
Via cet interface nous allons pouvoir renommer les champs que nous souhaitons. Pour cela, nous basculons en mode édition en cliquant sur l’icône correspondante . Deux nouveaux menus deviennent accessibles, mais ils ne vont pas nous intéresser pour le renommage de champ. Nous allons simplement double cliquer sur le Nom du champ à modifier. Par exemple, nous allons renommer le champ TopoOH en TopoStation. Nous double cliquons sur le Nom de ce champ et nous avons accès à son édition (Fig. 207).
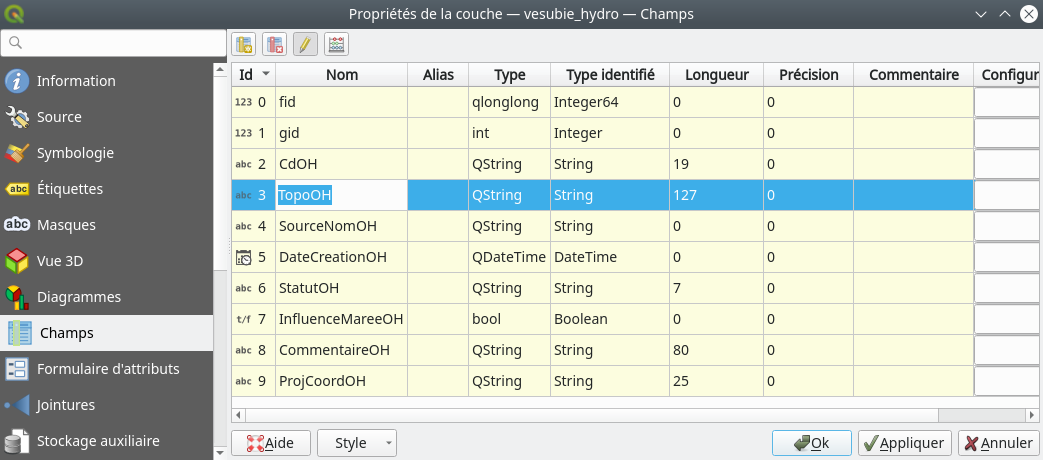
Fig. 207 Renommer un champ.
Il suffit alors de taper le nom désiré à la place de l’ancien.
Note
Notons bien que seul le nom du champ peut être changé. Son type n’est pas modifiable.
Une fois la modification effectuée, nous cliquons sur Appliquer puis OK. En ouvrant la table d’attributs de la couche, nous constatons bien que le nom a été modifié.
Avertissement
Si nous travaillons sur un shapefile, n’oublions pas que le nom des champs est limité à 8 caractères seulement.
Renommer un champ dans R
Version de R : 4.8.1
Renommer un champ dans R est possible mais la méthode à employer diffère selon que nous travaillons sur un objet sf ou SpatVector de terra. Nous verrons ici les deux méthodes.
Renommer un champ dans terra
Version de R : 4.3.1
Version de terra : 1.7.29
Dans cet exemple, nous chargeons un GeoPackage des départements de France métropolitaine dans un objet SpatVector nommé dep. Nous verrons comment renommer le nom d’un champ selon son indice et selon son nom.
# chargement de la couche
dep <- terra::vect('departements_france_L93.gpkg')
# on affiche le nom des champs
names(dep)
# on renomme le 1er champ
names(dep)[1] <- 'Code_Departement'
# on renomme le champ nommé 'Nom_Depart'
names(dep)[names(dep) == 'Nom_Depart'] <- 'Nom_Departement'
Renommer un champ dans sf
Version de R : 4.3.1
Version de sf : 1.0.12
Dans cet exemple, nous chargeons un GeoPackage des départements de France métropolitaine dans un objet sf nommé dep. Nous verrons comment renommer le nom d’un champ selon son indice et selon son nom.
# chargement de la couche
dep <- sf::st_read('departements_france_L93.gpkg')
# on affiche le nom des champs
names(dep)
# on renomme le 1er champ
names(dep)[1] <- 'Code_Departement'
# on renomme le champ nommé 'Nom_Depart'
names(dep)[names(dep) == 'Nom_Depart'] <- 'Nom_Departement'
Changer le format d’un champ
Il arrive qu’il soit nécessaire de changer le format d’un champ, de le convertir dans un autre type. Par exemple, un champ que nous voudrions avoir au format Entier est en fait en format Texte et nous ne pouvons donc pas le manipuler comme nous le souhaiterions. Dans ce cas, il est possible de transformer ce champ de type Texte en type Entier (ou Réel).
Dans la plupart des cas il n’est pas possible de changer le type d’un champ. La stratégie consiste donc à créer un nouveau champ dans le type désiré puis de le mettre à jour en copiant les valeurs de l’ancien champ en les convertissant.
Avertissement
Il n’est bien sûr pas possible de tout convertir en n’importe quoi. Le texte 95 pourra être converti en entier 95 et même en réel 95.0 mais le texte Val-d’Oise ne pourra évidemment pas être converti en format numérique.
Dans les exemples suivants nous allons convertir le champ des codes INSEE des communes des Hauts-de-Seine (92) qui sont en Texte en type Entier. Cette transformation nous permettrait par exemple de pouvoir facilement sélectionner tous les départements dont leur numéro est supérieur à 90 (si nous disposions des départements pour toute la France).
Convertir un champ dans QGIS
Version de QGIS : 3.18.3
Dans QGIS la procédure à suivre est simple. Après avoir chargé la couche à modifier nous ouvrons sa table attributaire (Fig. 208).
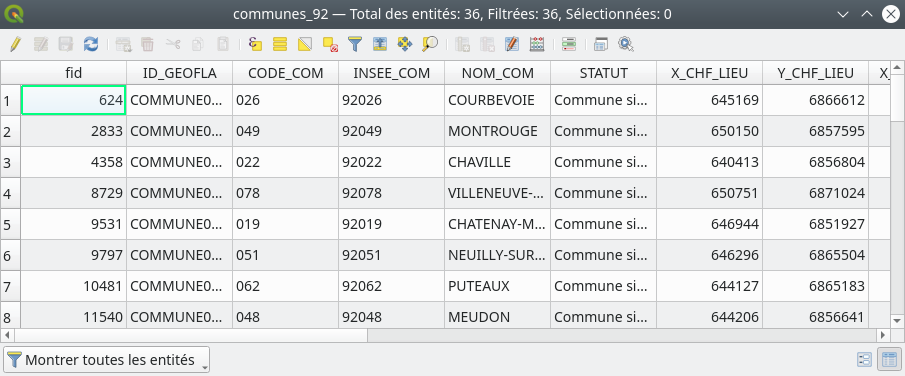
Fig. 208 Ouverture de la table attributaire à modifier.
Ici nous nous intéressons au champ INSEE_COMM. À première vue il contient des nombres mais on s’aperçoit que c’est en fait un champ textuel car ces « nombres » sont alignés sur la gauche des cellules. Les « vrais » nombres sont alignés sur la droite de la cellule comme nous pouvons le voir dans les champs de coordonnées des chefs lieux X et Y.
Si le doute persiste nous pouvons faire un clic droit sur la couches dans le panneau des couches puis . Le format des champs de la table attributaire s’affiche alors (Fig. 209).
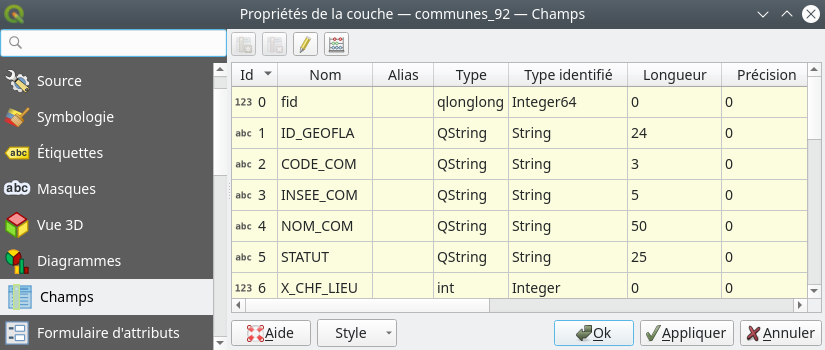
Fig. 209 Format des champs de la table attributaire.
Nous constatons bien que le champ INSEE_COM est bien de type String (Texte, pas l’accessoire de mode…). Pour créer un nouveau champ qui contiendra ce code INSEE mais au format numérique Entier (Integer) nous sélectionnons la couche à modifier dans le panneau des couches et nous ouvrons la calculatrice de champ en cliquant sur l’icône Ouvrir la calculatrice de champ . La calculatrice de champ s’ouvre alors (Fig. 210).
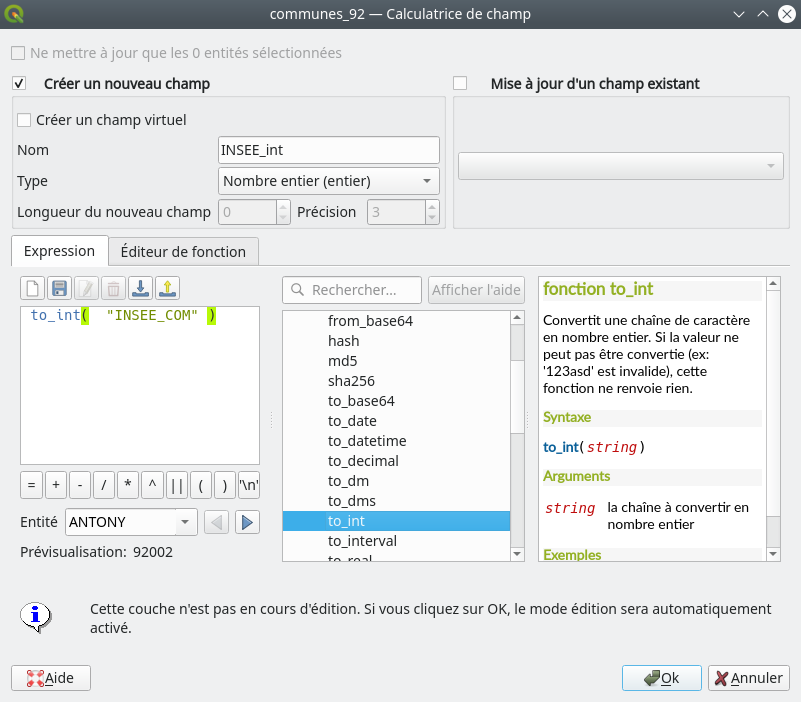
Fig. 210 Création d’un nouveau champ avec un nouveau format.
Nous cochons la case Créer un nouveau champ, dans le champ Nom, nous spécifions un nom pour le champ qui sera créé, par exemple INSEE_int et dans le champ Type nous spécifions le type du champ qui sera créé, à savoir Nombre entier (entier). Dans le bloc Expression, nous entrons l’expression qui permet la conversion
to_int("INSEE_COM")
Nous pouvons nous aider de l’explorateur de fonctions du panneau central : Conversions et Champs et valeurs pour construire cette expression. Puis nous cliquons sur OK.
Astuce
Il est tout à fait possible de convertir ce champ Texte vers un nombre réel plutôt que vers un entier. Dans ce cas, nous mettons le type de champ à Nombre décimal (réel) et nous utilisons la fonction to_real( ) plutôt que to_int( ).
En ouvrant la table attributaire nous constatons bien que le nouveau champ a été créé dans le bon format. Il ne reste plus qu’à quitter le mode édition de la couche et à la sauver.
Supprimer un champ
Les tables attributaires associées aux données vecteurs ne sont pas figées. L’utilisateur peut tout à fait supprimer un champ qui s’avérerait inutile ou faux.
Supprimer un champ dans QGIS
Version de QGIS : 3.16.1
La manipulation est très simple. Une fois notre couche vectorielle dont nous souhaitons supprimer un champ est chargée dans QGIS, nous commençons par ouvrir sa table attributaire. Une fois la table ouverte, nous passons en mode édition en cliquant sur l’icône (Fig. 211).
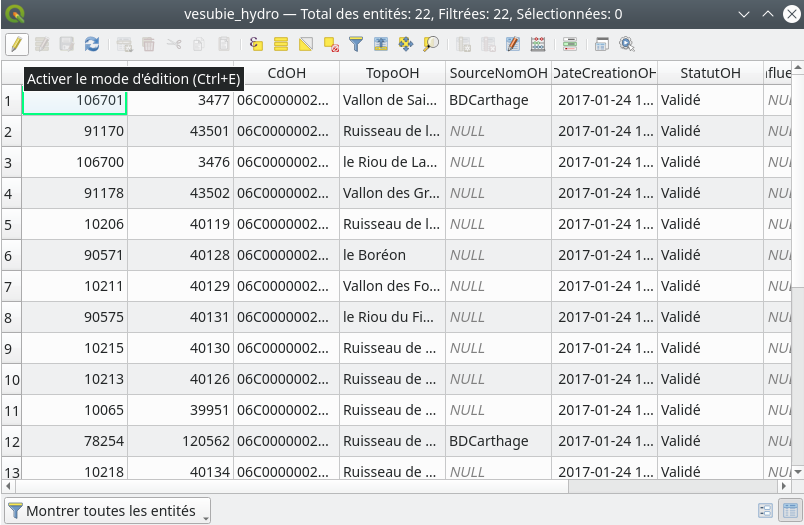
Fig. 211 Ouverture de la table en mode édition.
Une fois le mode édition activé, de nouveaux menus deviennent accessibles dans la barre d’outils. Nous y retrouvons notamment le menu Supprimer le champ  . Nous cliquons dessus et le menu suivant s’ouvre (Fig. 212).
. Nous cliquons dessus et le menu suivant s’ouvre (Fig. 212).
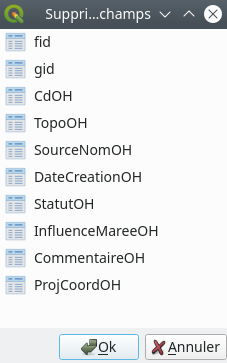
Fig. 212 Liste des champs à supprimer.
Ce menu liste tous les champs de la couche et invite l’utilisateur à sélectionner le ou les champs à supprimer. Par exemple, si nous souhaitons supprimer les champs CdOH, TopoOH et CommentaireOH, nous les sélectionnons en maintenant la touche Ctrl enfoncée (Fig. 213).
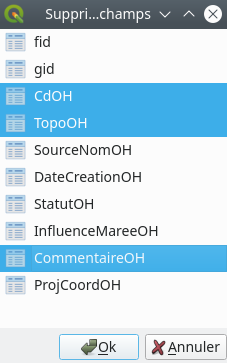
Fig. 213 Sélection des champs à supprimer.
Une fois cette sélection effectuée, il ne reste plus qu’à cliquer sur OK. Nous revenons à la table attributaire et nous constatons que les champs en question ont bien été supprimés. Il ne reste plus qu’à cliquer sur Enregistrer les modifications et à sortir du mode édition en recliquant sur l’icône .
Supprimer un champ dans R
Nous pouvons supprimer un ou plusieurs champs d’une table attributaire d’un objet vecteur dans R. La méthode diffère selon que nous travaillons sur un objet sf ou SpatVector. Nous verrons ici les deux.
Supprimer un champ avec terra
Version de R : 4.3.1
Version de terra : 1.7.29
Pour supprimer un champ depuis un objet SpatVector, il va falloir passer par la librairie tidyterra et sa fonction select. Dans l’exemple ci-après, nous allons supprimer les champs POP_1999 et Nom_reg d’un SpatVector des départements de France métropolitaine.
# chargement du vecteur
dep <- terra::vect('departements_france_L93.gpkg')
# suppression des champs
dep <- dep %>% tidyterra::select(-one_of('POP_1999', 'Nom_reg'))
Supprimer un champ avec sf
Version de R : 4.3.1
Version de sf : 1.0.12
Avec un objet sf, le plus simple est d’utiliser la fonction select de la librairie dplyr. Ici, nous allons travailler sur une couche vecteur des départements français chargés sous forme d’un objet sf. Le code pour supprimer un ou plusieurs champs est présenté ci-dessous.
# chargement des librairies utilisées
library(sf)
library(dplyr)
# chargement de la couche
dep <- sf::st_read("departements_france_L93.gpkg")
# supprimer un seul champ
dep3 <- dep %>% select(-'POP_1999')
# supprimer plusieurs champs en même temps
dep4 <- dep %>% select(-one_of('POP_1999', 'Nom_reg'))
Nous avons ainsi créé une couche vecteur dep3 dont le champ POP_1999 seul a été supprimé. Ensuite, une couche vecteur dep4 a été créée dans laquelle, les champs POP_1999 et Nom_reg ont été supprimés en une seule fois.
Astuce
D’autres options existent pour sélectionner les champs à supprimer. Cette page en présente quelques unes intéressantes.
Sélectionner un champ dans R
Version de R : 4.3.1
Il est parfois utile de supprimer les attributs qui ne nous sont pas utiles dans notre analyse afin d’alléger ses traitements. Dans cet exemple, nous allons sélectionner les champs Code_Depar et POP_1999 depuis un SpatVector des départements de France métropolitaine. La manipulation revient à supprimer tous les champs sauf ceux-ci.
# chargement du vecteur
dep <- terra::vect('departements_france_L93.gpkg')
# sélection des champs
dep_new <- dep[c('Code_Depar', 'POP_1999')]
Astuce
La manipulation est la même pour un objet sf.
Ordonner les champs
Les tables attributaires associées aux données vecteurs ne sont pas figées. L’utilisateur peut tout à fait modifier l’ordre des champs, i.e. l’ordre des colonnes.
Ordonner les champs dans R
Il est possible de facilement réordonner l’ordre des champs d’une table attributaire dans R.
Ordonner les champs avec terra
Version de R : 4.3.1
Version de terra : 1.7.29
Dans cet exemple, nous allons réordonner les champs d’un SpatVector des départements de France métropolitaine.
# chargement du vecteur
dep <- terra::vect('departements_france_L93.gpkg')
# réordonner les champs
dep_new <- dep[c('Nom_reg', 'code_reg', 'Nom_Depart', 'Code_Depar', 'POP_1999', 'SUP_KM2')]
Ordonner les champs avec sf
Version de R : 4.3.1
Version de sf : 1.0.12
Si nous travaillons avec un objet sf, le plus simple est d’utiliser la fonction select de la librairie dplyr. Dans l’exemple, nous allons travailler sur une couche vecteur des départements français, au préalable chargée en tant qu’objet sf. Le code ci-dessous montre un exemple de changement d’ordre des colonnes.
# chargement des librairies utilisées
library(sf)
library(dplyr)
# chargement de la couche
dep <- sf::st_read("departements_france_L93.gpkg")
# changement de l'ordre des colonnes de la table attributaire
dep5 <- dep %>% select('Nom_Depart', 'Code_Depar', 'code_reg', 'SUP_KM2')
Nous avons ainsi créé une couche vecteur dep5 dont les champs sont maintenant dans l’ordre tel qu’indiqué dans la fonction select().
Jointure attributaire
La jointure attributaire est une opération fondamentale en SIG et en exploration de bases de données en général. Ce type de jointure permet de relier deux tables, dans le cas des SIG nous parlerons de deux couches vecteurs, entre elles grâce à un champ commun. Par exemple, si nous possédons deux couches de communes d’une région donnée, avec des attributs différents (le Nom pour l’une et la Population pour l’autre) nous pouvons les relier si elles possèdent un champ commun. Dans l’exemple, le champ commun pourrait être le code INSEE de la commune (Fig. 214).

Fig. 214 Exemple de jointure attributaire sur un champ commun.
Le champ commun doit être de même type, entier ou texte dans la plupart des cas. Si le champ est de type texte, les codes textuels doivent être rigoureusement identiques : même casse, même orthographe, … Il est souvent recommandé de passer par des codes officiels plutôt que par les champs textuels quand c’est possible. Par exemple, pour lier deux couches selon le Département il sera plus judicieux de passer par le code (01, 02 …, 95) que par le nom. En effet, nous sommes sûrs du numéro 95 alors que Val-d’Oise peut être orthographié val d’oise, val-d’oise, val d oise, …
Notons que si plusieurs lignes, i.e. plusieurs entités, d’une des couches possèdent le même code mais que ce code n’est représenté que par une seule entité dans la seconde table, il faudra faire attention à ne garder qu’une liaison ou bien toutes les liaisons possibles, au prix d’une multiplication des entités.
Jointure attributaire dans QGIS
Version de QGIS : 3.22.3
Les jointures attributaires sont très faciles à mettre en place dans QGIS. Dans cet exemple d’application, nous allons joindre la couche des lieux de culte en région Île-de-France avec la couche des communes d’Île-de-France. Le but sera d’associer à chaque lieu de culte le nom de la commune dans lequel il se situe. Le champ commun aux deux couches que nous utiliserons sera la code INSEE de la commune. Dans le cas de la couche des communes il est connu sous le nom de INSEE_COM et dans la couche des lieux de culte CODE_INSEE. Dans les deux cas il s’agît d’un champ de type texte (string) (Fig. 215).
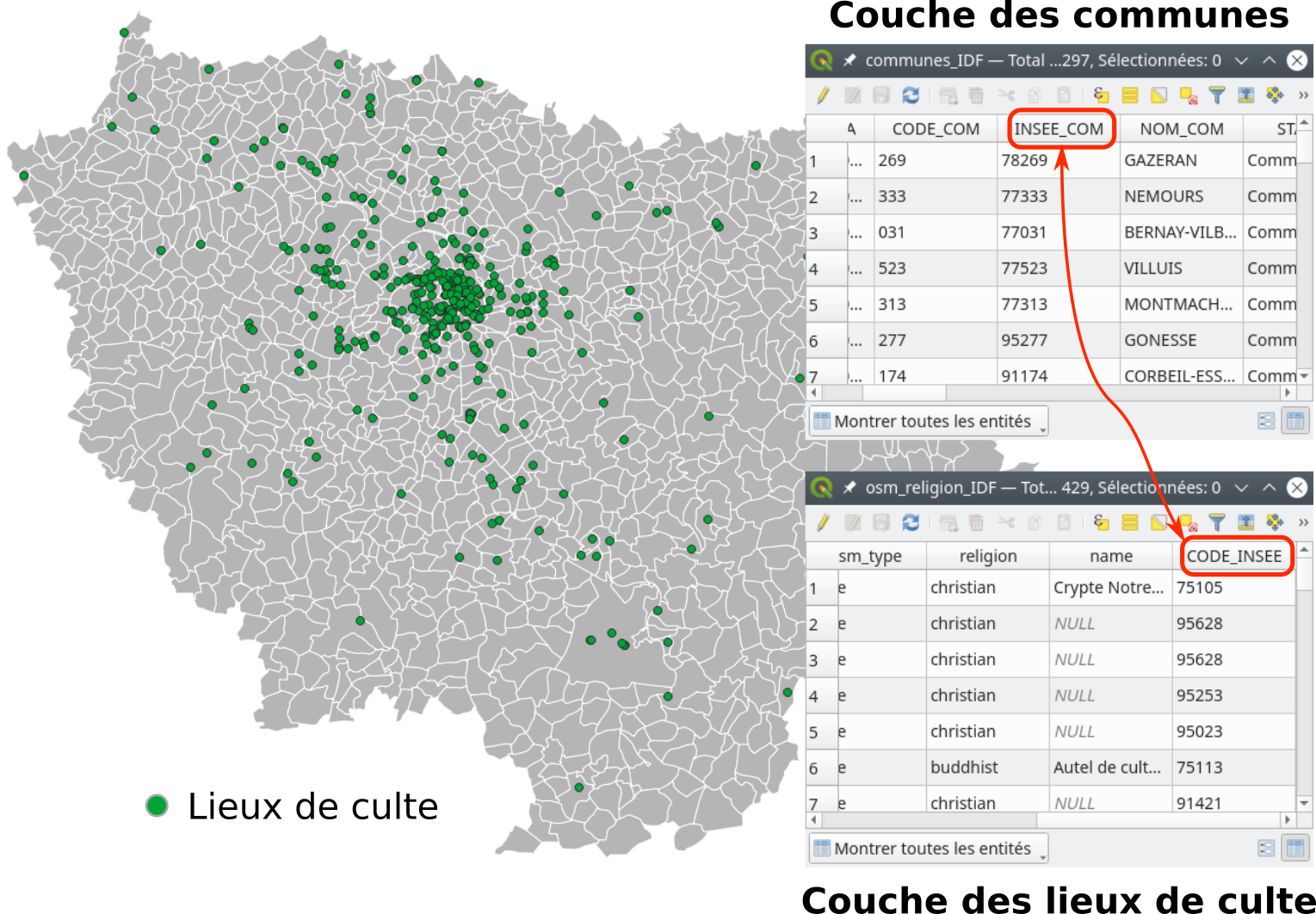
Fig. 215 Les deux couches à joindre ouvertes dans QGIS.
Une fois les deux couches ouvertes dans QGIS, nous faisons un clic droit sur la couche sur laquelle nous souhaitons rapatrier les attributs, à savoir la couche des lieux de culte dans notre cas. Une fois le clic droit effectué, nous cliquons sur , puis nous cliquons sur l’icône 
Ajouter une nouvelle jointure en bas du panneau principal. La fenêtre suivante s’ouvre (Fig. 216).
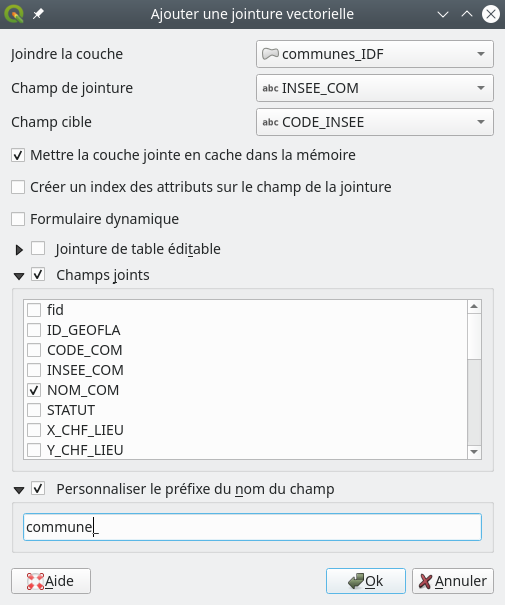
Fig. 216 Paramétrage de la jointure attributaire dans QGIS.
Dans le champ Joindre la couche nous sélectionnons la couche à joindre, à savoir la couche communes_IDF. Dans le champ Champ de jointure, nous indiquons le champ qui sert pour la jointure dans cette couche, ici INSEE_COM, dans le champ Champ cible nous indiquons le champ pour la jointure dans la couche initiale (celle des leiux de culte), ici CODE_INSEE. Nous pouvons cocher l’option Champs joints afin de ne joindre que le ou les champs qui nous intéressent, dans notre cas NOM_COM. Sinon par défaut, tous les champs sont joints. Enfin, en cochant l’option Personnaliser le préfixe du nom du champ, nous pouvons indiquer un préfixe pour le champ qui sera rapatrié, ici commune. Puis nous cliquons sur OK, puis encore OK.
Si nous ouvrons maintenant la table attributaire de la couche des lieux de culte, le nom de la commune a bien été rapatrié dans le champ commune_NOM_COM. Cependant, à ce stage la jointure n’est pas sauvée. Afin de vraiment la sauvegarder, il est nécessaire d’exporter notre couche dans une nouvelle couche en faisant un clic droit dessus dans le panneau des couches et en sélectionnant
Avertissement
Pensez bien à sauvegarder le résultat de la jointure en exportant la couche résultat dans une nouvelle couche.
Jointure attributaire dans R
Version de R : 4.8.1
Il est possible de faire des jointures attributaires dans R. La méthode diffère un peu selon que nous travaillons sur un objet sf ou SpatVector. Nous verrons les deux. Dans les deux cas, nous commencerons par charger deux GeoPackage des départements de Frane métropolitaine. Le premier, dep_sup, contient un champ avec les codes des départements nommé Code_Departement et un champ contenant les superficies des départements. Le second, dep_pop, contient un champ avec les codes des départements nommé Code_Depar et un champ contenant les populations des départements. L’objectif est de joindre les deux couches selon le code du département afin d’obtenir une couche finale contenant trois champs : code, superficie et population.
Jointure attributaire dans terra
Version de R : 4.3.1
Version de terra : 1.7.29
La jointure se fait à l’aide de la fonction merge de terra.
# chargement des couches
dep_sup <- terra::vect('dep_sup.gpkg')
dep_pop <- terra::vect('dep_pop.gpkg')
# on joint les deux couches par le champ qui contient le code du département
dep_sup_pop <- terra::merge(dep_sup, dep_pop, by.x='Code_Departement', by.y='Code_Depar')
Avertissement
Nous n’avons ici conservé que les entités qui étaient présentes sur les deux couches initiales, c’est-à-dire que nous avons fait une Inner Join. D’autres types de jointure sont possibles, à utiliser selon les besoins.
Jointure attributaire dans sf
Version de R : 4.3.1
Version de sf : 1.0.12
Ces jointures se font à l’aide de la fonction merge(). Cette fonction merge() ne fonctionne pas sur deux objets de type sf. Il va falloir en transformer un en simple dataframe (ce qui revient à ne conserver que sa table attributaire) puis joindre ce simple dataframe à l’autre objet resté de type sf.
# chargement des couches
dep_sup <- terra::vect('dep_sup.gpkg')
dep_pop <- terra::vect('dep_pop.gpkg')
# on transforme la seconde couche en simple dataframe
dep_pop <- sf::st_drop_geometry(dep_pop)
# on joint le 'sf' avec le le simple dataframe
dep_sup_pop <- merge(x=dep_sup, y=dep_pop, by.x='Code_Departement', by.y='Code_Depar')
Nous avons ainsi créé une nouvelle couche qui contient les champs des deux couches initiales.
Avertissement
Nous n’avons ici conservé que les entités qui étaient présentes sur les deux couches initiales, c’est-à-dire que nous avons fait une Inner Join. D’autres types de jointure sont possibles, à utiliser selon les besoins.
Sélection attributaire
Un des points fondamentaux des SIG est de permettre des sélections attributaires, aussi appelées requêtes attributaires. La sélection d’entités basée sur des critères fondés sur les attributs d’une couche est un aspect fondamental des SIG. C’est même presque la raison d’être des SIG. Ces sélections peuvent être très simples ou très complexes. Selon les besoins et les connaissances de l’utilisateur, les sélections sont un outil puissant. L’interrogation des données attributaires se fait selon le langage SQL. Ce langage a l’avantage d’être simple pour des requêtes basiques mais peut se complexifier pour mener à bien des requêtes complexes.
Ce type de requêtes est qualifié de requêtes attributaires, à mettre en parallèle des requêtes spatiales présentées dans un autre chapitre.
Requêtes attributaires dans QGIS
Version de QGIS : 3.16.1
Dans QGIS, les requêtes attributaires se font simplement via le menu Sélection par expression. Ce menu est accessible depuis la barre d’outils de sélection (Fig. 217). Il faut au préalable avoir sélectionné la couche à interroger dans le panneau de couches. Dans cet exemple, nous travaillerons sur la couche des communes des Hauts-de-Seine (92) communes_92.gpkg.
Fig. 217 Ouverture du menu de sélection par expression.
Plus précisément, le menu à utiliser se nomme Sélectionner des entités à l’aide d’une expression… dont l’icône ressemble à ça . Une fois ce menu sélectionné, la fenêtre de Sélection par expression s’affiche (Fig. 218).
Fig. 218 Le menu de sélection par expression.
Dans ce menu, nous retrouvons sur la gauche un panneau Expression. C’est dans ce panneau que nous entrerons notre expression en SQL nous permettant de faire notre requête. Dans le panneau central, nous trouvons des menus déroulants contenant des fonctions qui vont nous servir pour construire notre requête. Ces fonctions sont rangées par grand thème : celles qui permettent de manipuler le texte (Chaîne de caractères), celles portant sur les conversions de type (Conversions), celles permettant de requêter sur la géométrie (Géométrie), etc
Un menu déroulant que nous utiliserons tout le temps est celui permettant d’accéder aux champs de la couche Champs et valeurs (Fig. 219).
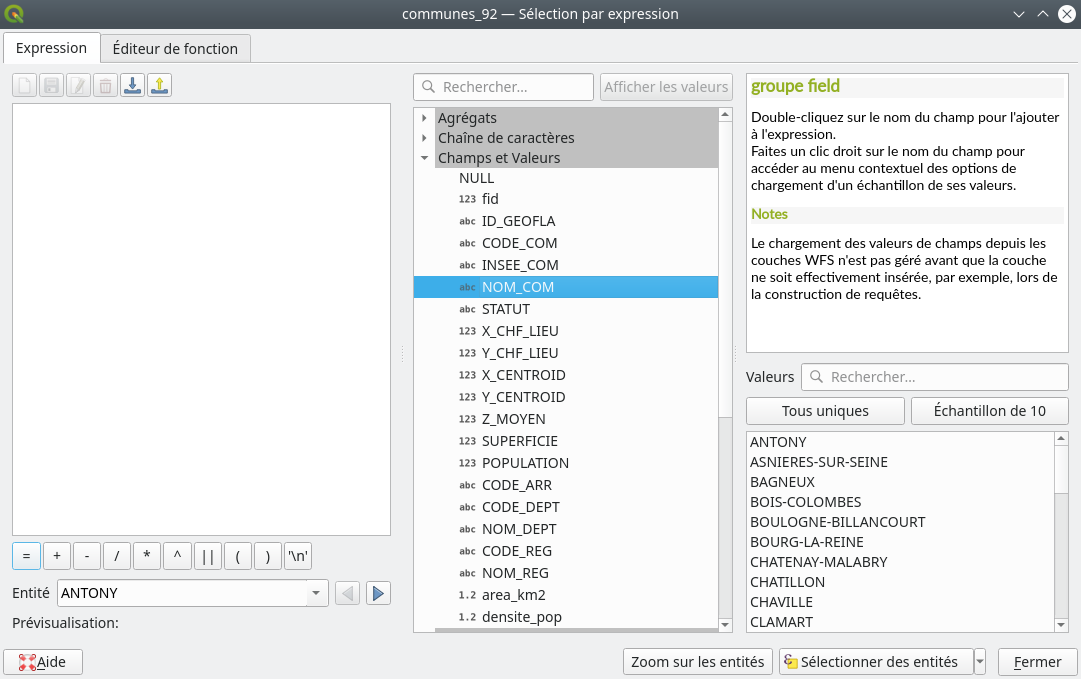
Fig. 219 Liste des champs de la couche et de leurs valeurs.
En déroulant ce menu, nous accédons à la liste des champs présents dans cette couche. Nous pouvons ensuite cliquer sur un champ et demander à QGIS de nous lister toutes les valeurs uniques de ce champ ou un échantillon de dix valeurs via le panneau en bas à droite. Cette fonctionnalité s’avère très intéressante pour éviter de faire des fautes lorsqu’on requête sur un champ texte. Par exemple, dans notre cas, ça nous évite de chercher Boulogne-Billancourt, boulogne billancourt, boulogne-billancourt … mais d’avoir directement accès à l’orthographe tel qu’enregistré dans la couche.
Avertissement
La casse d’un mot (i.e. le fait qu’il soit écrit en majuscules ou en minuscules) est important. Ainsi Malakoff et MALAKOFF sont deux mots différents.
Il faut être prudent avec cette fonctionnalité de lister toutes les valeurs uniques. Sur un champ contenant des milliers de valeurs différentes (typiquement un champ numérique) QGIS va avoir du mal à les lister.
Requête basique
Nous allons commencer par construire une requête très basique mais fondamentale. Nous allons sélectionner les communes qui ont plus de 50 000 habitants. Nous allons donc interroger le champ Population.
Pour cela, dans le panneau central, dans le menu Champs et valeurs, nous double cliquons sur POPULATION. Le champ apparaît alors dans le panneau de gauche encadré de guillemets. Les guillemets font partie de la syntaxe SQL. Elles sont un marqueur pour bien préciser que le texte entre ces guillemets renvoie à un nom de champ.
Ensuite, de façon tout à fait naturel, nous entrons la suite de l’expression : > 50000 (Fig. 220).
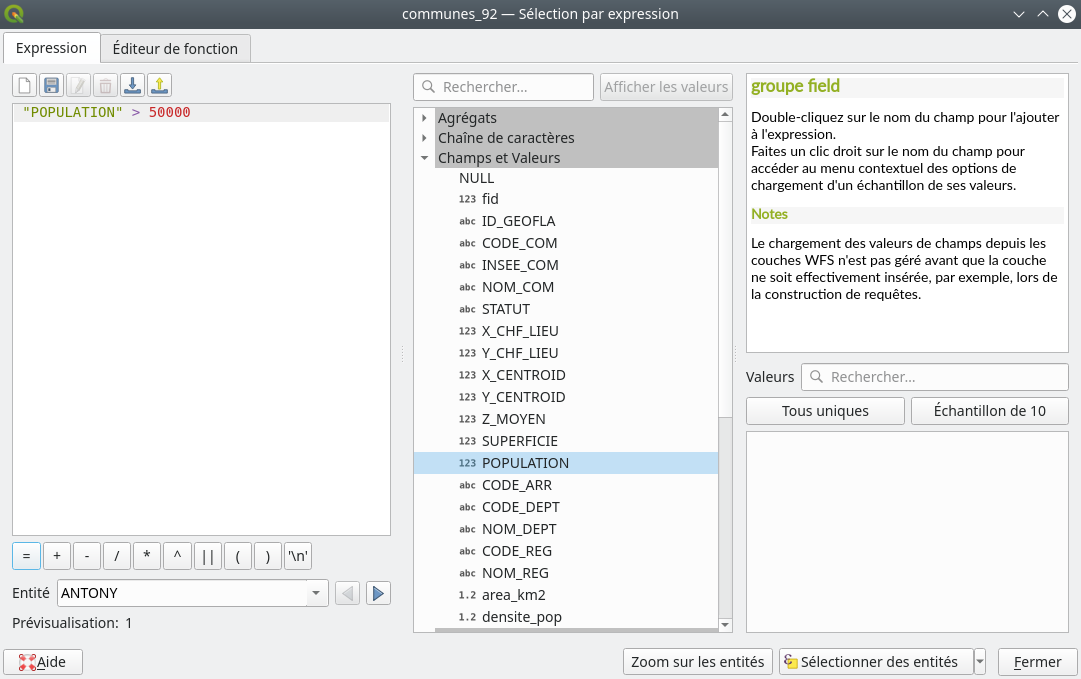
Fig. 220 Requête permettant de sélectionner les communes de plus de 50 000 habitants.
Il n’y a plus qu’à cliquer sur Sélectionner des entités. Les communes qui répondent à ce critère apparaissent en jaune (Fig. 221).
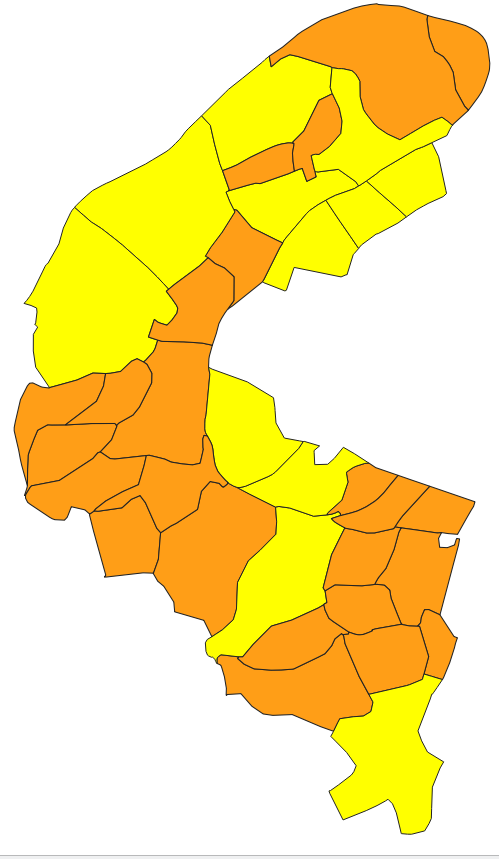
Fig. 221 Résultat de la requête, les communes correspondant au critère apparaissent en jaune.
En ouvrant la table attributaire, les lignes correspondantes aux communes sélectionnées sont surlignées en bleu. Nous avons également le compte de communes sélectionnées en haut du cadre de la fenêtre de cette table, ici 12 (Fig. 222).
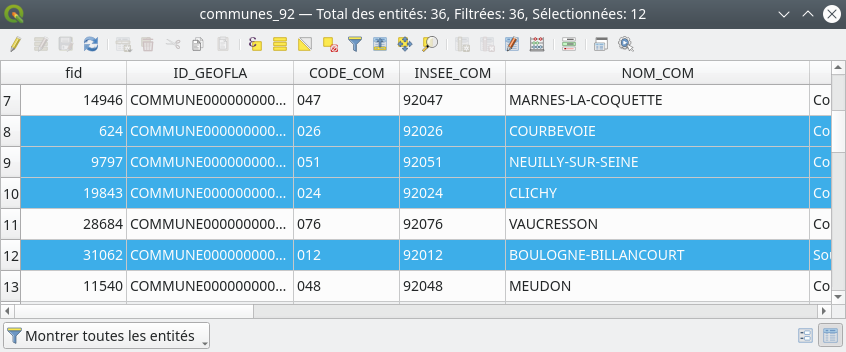
Fig. 222 12 communes répondent au critère de sélection.
Note
Pour déselectionner les entités, le plus simple est de cliquer sur l’icône Déselectionner toutes les entités  .
.
Requête avec des booléens
Il est souvent nécessaire d’inclure dans notre requête des opérateurs booléens comme Et, Ou … Par exemple, nous pouvons avoir besoin de ne sélectionner que les communes dont la population est comprise entre 30000 et 50000 habitants. Dans ce cas, l’opérateur Et (And) sera nécessaire. Notre requête s’écrira alors "POPULATION" > 30000 AND "POPULATION" < 50000 (Fig. 223).
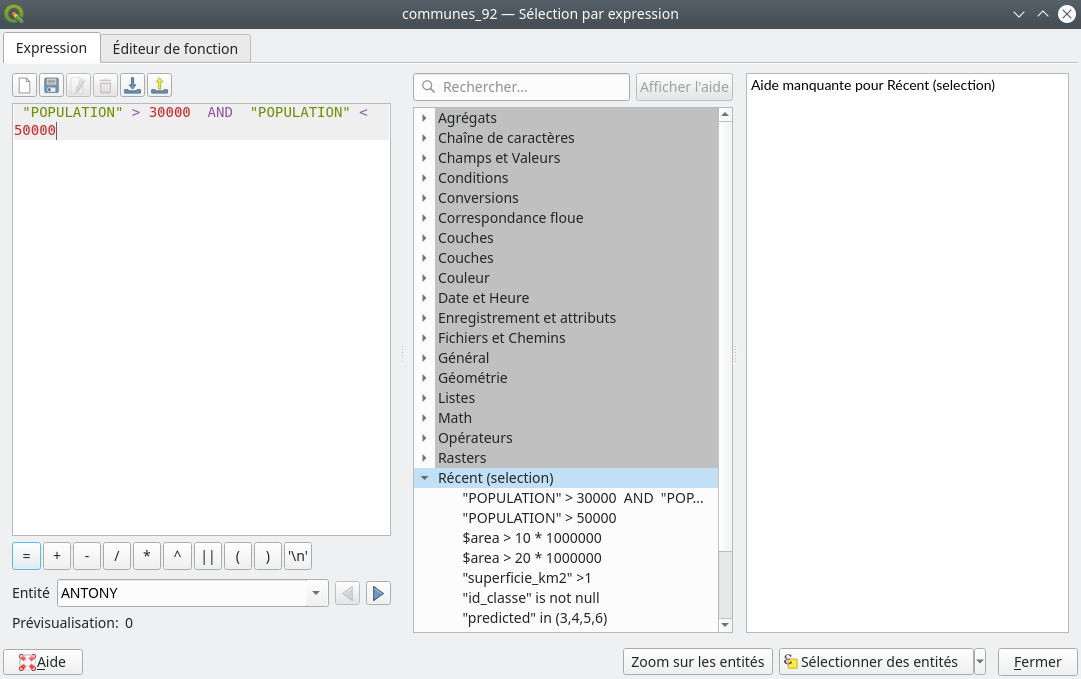
Fig. 223 Sélection utilisant un booléen.
Comme précédemment, les communes répondant à ce double critère apparaissent en jaune.
Une fonctionnalité intéressante de QGIS est de se servir d’une fonction booléenne un peu « cachée ». C’est une sorte de fonction booléenne par bricolage. Imaginons que nous souhaitions sélectionner les communes précédentes et aussi la commune de Vaucresson (qui n’entre pas dans le critère). La manière élégante et SQL de procéder est d’entrer la requête suivante ("POPULATION" > 30000 AND "POPULATION" < 50000) or "NOM_COM" = 'VAUCRESSON'. Nous remarquons l’ajout de parenthèse autour de la première condition et l’apparition du booléen OR suivi de la seconde condition. L’exécution de cette requête donne bien le résultat attendu.
Une manière moins élégante mais parfois plus rapide est de se servir de la fonctionnalité Ajouter à la sélection actuelle. Concrètement, dans un premier temps, il suffit d’entrer seulement la requête principale dans le panneau Expression "POPULATION" > 30000 AND "POPULATION" < 50000 puis de l’exécuter normalement en cliquant sur Sélectionner des entités. Une fois les entités sélectionnées, nous les gardons bien sélectionnées et nous entrons maintenant la requête secondaire "NOM_COM" = 'VAUCRESSON'. Mais au lieu de cliquer sur Sélectionner des entités, nous cliquons sur Ajouter à la sélection actuelle (Fig. 224).
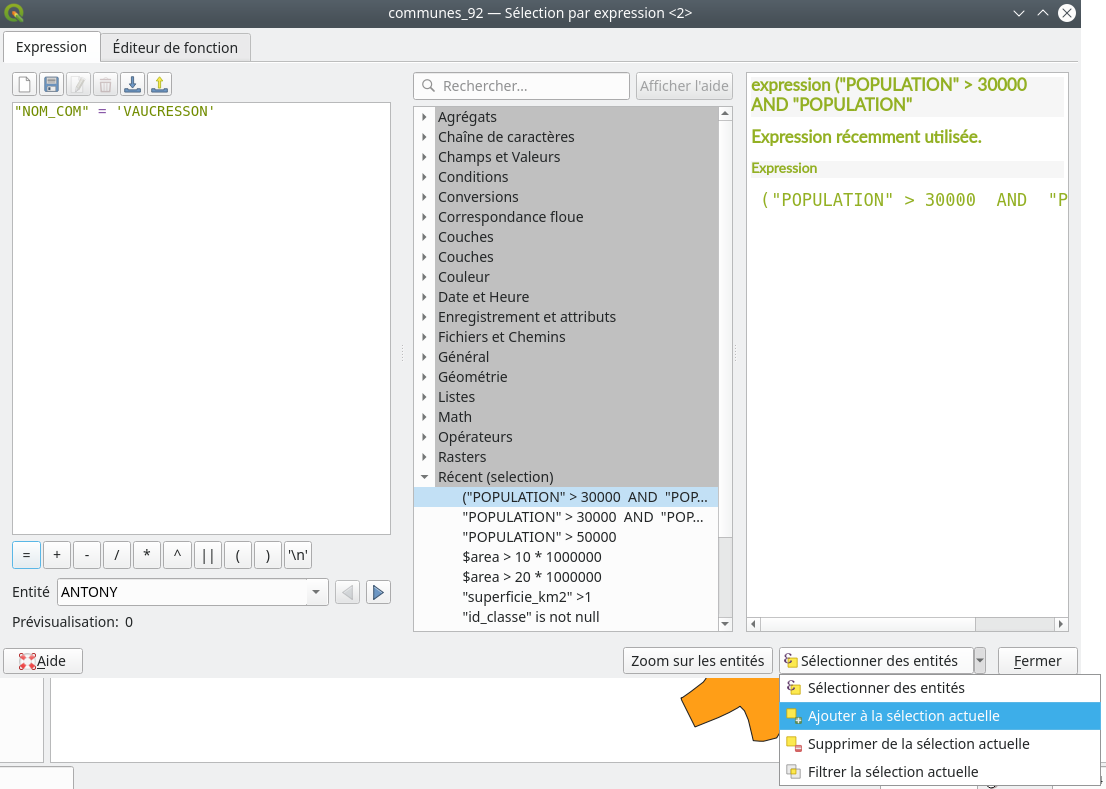
Fig. 224 Ajouter un résultat de sélection à une sélection précédente.
Une fois cette seconde requête exécutée de cette façon, la commune de Vaucresson est bien ajoutée à notre précédente sélection.
Un point encore plus intéressant est que ce principe peut être utilisé pour des sélections du type : sélectionne moi toutes ces communes sauf celle-ci. Le sauf peut être fastidieux à retranscrire en SQL. Ici, par exemple, nous allons sélectionner nos communes comprises entre 30000 et 50000 habitants sauf la commune de Puteaux qui répond pourtant au critère. La façon élégante serait d’écrire la requête suivante ("POPULATION" > 30000 AND "POPULATION" < 50000) AND "NOM_COM" != 'PUTEAUX'. Nous retrouvons nos parenthèses autour de la requête principale et notre requête secondaire mais cette fois-ci liée par un AND et présentant l’opérateur != qui signifie différent de. Notre requête se lit donc comme suit : Sélectionne moi les communes qui ont plus de 30000 habitants et moins de 50000 habitants et dont le nom n’est pas Puteaux. Ça reste gérable mais on sent que ça peut vite se compliquer.
Dans ce cas, un moyen simple est de commencer par exécuter la requête principale seule. Une fois les communes sélectionnées, nous retournons dans le menu de sélection par expression et nous y entrons la requête simple "NOM_COM" = 'PUTEAUX'. Puis, au lieu de cliquer sur Sélectionner des entités, nous cliquons sur Supprimer de la sélection actuelle (Fig. 225).
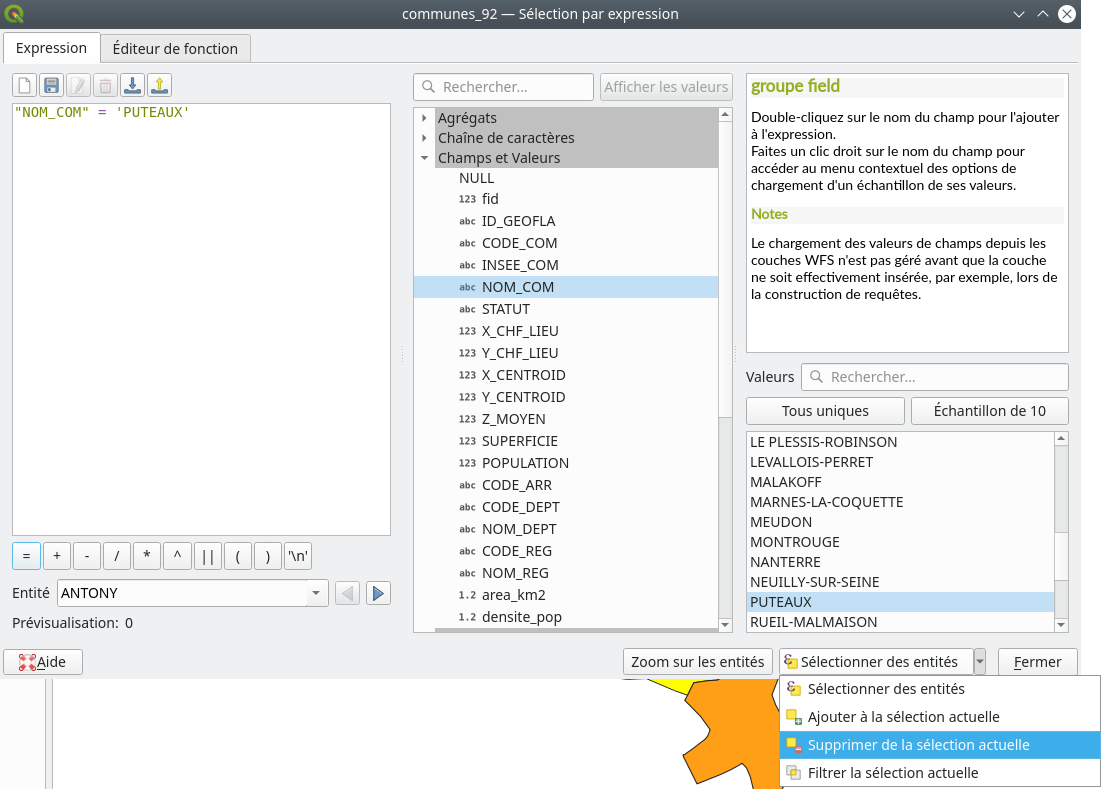
Fig. 225 Enlever une entité de la sélection précédente.
Ainsi, la commune qui répond au second critère est enlevée de la sélection précédente. C’est donc un moyen de faire des requêtes booléennes sans trop de gymnastique mentale.
Requête avec des opérateurs textuels
Il est possible de faire des requêtes un peu poussées sur des champs de type String (Texte). Pour cet exemple, nous allons charger la couche des communes d’Île-de-France « communes_IDF.gpkg ». Nous allons sélectionner les communes dont le code INSEE commence par 95. Nous allons donc extraire les communes du Val-d’Oise. Ce code se trouve dans le champ INSEE_COM. Nous ouvrons le menu de sélection par expression. Nous allons voir comment dire en SQL « Sélectionne moi toutes les communes dont le champ INSEE_COM commence par 95 ». La syntaxe ne se devine pas.
La requête s’écrit ainsi "INSEE_COM" like '95%'. Les deux choses importantes à saisir sont la présence de mot clef like et du symbole %. Like est utilisé dans le cas d’une comparaison pour un champ texte. Le % est un caractère joker qui signifie n’importe quel caractère. Ainsi 95% équivaut à un texte commençant par 95 suivi de n’importe quel caractère (un ou plusieurs, sans importance) (Fig. 226).
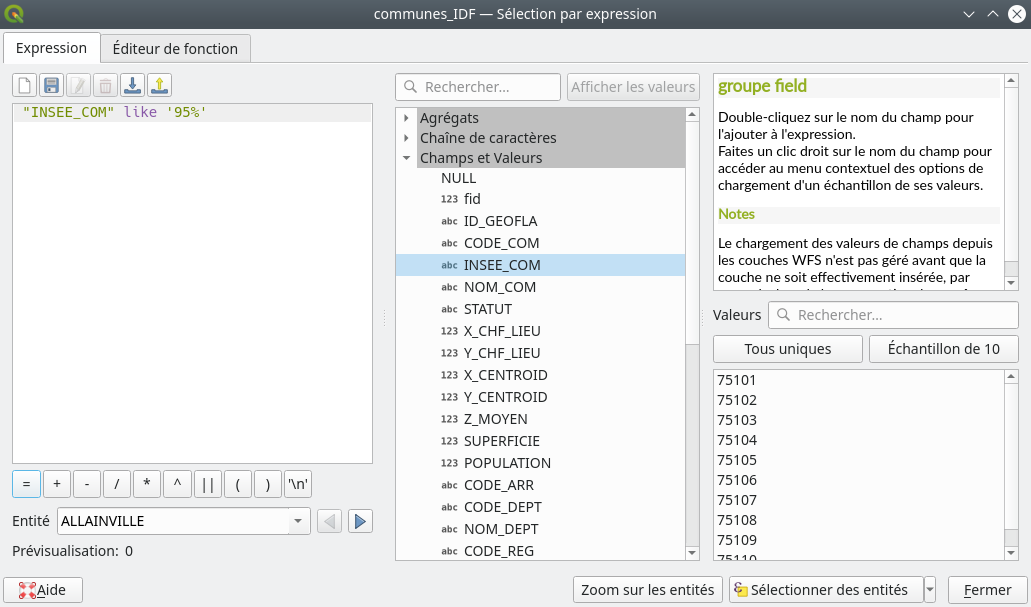
Fig. 226 Sélectionner les communes dont le code commence par 95.
Dans la même logique, il est possible de sélectionner les communes dont le nom est composé, c’est-à-dire qui contiennent le caractère -. La requête sera alors "NOM_COM" like '%-%'. Nous sélectionnons ici les communes dont le nom commence par n’importe quel caractère suivi d’un - puis suivi de n’importe quel caractère. Nous nous apercevons que quasiment la moitié des communes d’Îlde-de-France présente un nom composé !
Il est également possible de sélectionner des entités dont un champ texte fait partie d’une liste donnée. Par exemple si nous souhaitons sélectionner les communes de Cergy, Pontoise, Malakoff et Bobigny, nous sommes, de prime abord, tentés d’écrire la requête suivante : "NOM_COM" = 'CERGY' or "NOM_COM" = 'PONTOISE' or "NOM_COM" = 'MALAKOFF' or "NOM_COM" = 'BOBIGNY'. Cette requête va parfaitement fonctionner mais sa lisibilité laisse à désirer. Nos chances d’oublier une « ou un = sont importantes.
Il existe un moyen plus simple de faire ce genre de sélection. Nous pouvons nous servir du mot clef SQL in, de la façon suivante : "NOM_COM" in ('CERGY', 'PONTOISE', 'MALAKOFF', 'BOBIGNY'). Nous avons ici quelque chose de beaucoup plus lisible et moins source d’erreur.
Mais comment dire que nous souhaiterions sélectionner toutes les communes de la région sauf ces quatre ci ? La solution SQL consiste à écrire la requête suivante : "NOM_COM" not in ('CERGY', 'PONTOISE', 'MALAKOFF', 'BOBIGNY'). Le mot clef not permet de sélectionner ce qui n’est pas dans la liste. Mais une technique de Sioux consiste à sélectionner ces quatre communes comme dans l’exemple précédent puis d”inverser la sélection grâce à la fonction Inverser la sélection  se trouvant dans la barre d’outils de la table attributaire.
se trouvant dans la barre d’outils de la table attributaire.
Requête basée sur la géométrie
Jusqu’ici nous avons vu des requêtes qui n’ont fait intervenir aucun concept géographique. Or l’avantage d’un SIG est justement que les entités gérées sont spatialisées et disposent donc d’attributs spatiaux. Pour une entité de type polygone nous pouvons donc avoir accès à sa superficie.
Ce fait est tout à fait intéressant lorsque nous souhaitons sélectionner des entités selon leurs tailles, même si aucun champ de superficie n’existe. Nous allons par exemple sélectionner les communes d’Île-de-France de plus de 20 km2. Nous retournons dans le menu de sélection par expression et en nous aidant du menu déroulant Géométrie qui se trouve dans le panneau central nous pouvons entrer directement la requête suivante $area > 20 * 1000000. La fonction $area retourne la superficie de chaque entité exprimée dans les unités du SCR, à savoir ici des mètres. C’est pourquoi nous multiplions par 1000000 notre critère de taille. Souvent, pour ce type de requête nous sommes tentés de d’abord créer un vrai champ Superficie puis ensuite de requêter dessus, alors que ce n’est absolument pas nécessaire (Fig. 227).
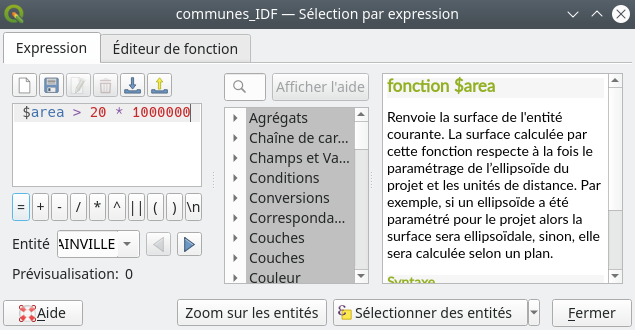
Fig. 227 Sélectionner sur la superficie sans champ de superficie.
Cet aspect peut bien sûr être couplé aux champs présents. Par exemple, il est tout à fait possible de sélectionner les communes dont la densité d’habitants est supérieure à 50 habitants par kilomètres carrés via la requête suivante : ("POPULATION" / ( $area / 1000000)) > 50. Il faut bien faire attention aux parenthèses et à la conversion de la superficie et la requête donne le résultat escompté. Cette requête remplace le fait de créer un champ Superficie puis un champ Densité puis une requête sur ce dernier champ.
Requêtes attributaires dans R
Une fois une couche vecteur chargée dans R, il est possible d’y effectuer tout type de requêtes attributaires. Faire ce type de requêtes dans R est un moyen puissant pour chaîner les opérations en évitant d’écrire en dur sur le disque tous les fichiers intermédiaires.
Sélection attributaire avec terra
Version de R : 4.3.1
Version de terra :
Dans cet exemple, nous commençons par charger les départements de France métropolitaine dans un objet SpatVector, qui possède un attribut SUP_KM2 qui correspond à la superficie de chaque département. Puis nous allons créer un nouvel objet SpatVector dans lequel nous ne stockerons que les départements dont la superficie est supérieure à 7000 km 2. Cette sélection se fait à l’aide de la fonction subset de terra.
grands_dep <- terra::subset(dep, dep$SUP_KM2 >= 7000)
Sélection attributaire avec sf
Version de R : 4.3.1
Version de sf : 1.0.12
Dans cet exemple, nous effectuerons une requête sur une couche vecteur contenant les départements français stockée dans une variable nommée departements sous la forme d’un objet sf. Cette couche possèse un champ nommé superficie contenant les superficies de chaque département exprimé en km 2. Dans l’exemple, nous sélectionnons tous les départements dont la superficie est supérieure à 1500 km 2. Nous sauvons le résultat de cette sélection dans une variable nommée grands_dep. Cette sélection n’est finalement rien d’autre qu’un filtre au sens de R, comme il est possible de les appliquer à tout objet de type dataframe.
grands_dep <- dep[(dep$superficie > 1500),]
Note
Se référer à la documentation de base de R pour bien saisir la syntaxe employée pour les filtres.
Regrouper des entités selon un attribut
En SIG, comme en gestion de bases de données en général, il est souvent nécessaire de dériver une nouvelle table, une nouvelle couche en SIG, à partir d’une table existante, par regroupement de géométries. Ce traitement est connu sous différents noms : Regrouper / Regroupement / Agrégation ou par son nom anglais Dissolve. Concrètement, il s’agît de regrouper des géométries en se basant sur un attribut qu’elles ont en commun.
Par exemple, sur la figure suivante (Fig. 228), nous disposons d’une couche vectorielle contenant les polygones des communes pour la France. Pour chaque commune, nous disposons de différents attributs comme la population ou le département d’appartenance. Nous souhaitons en dériver une couche vectorielle de polygones, où chaque polygone sera un département. Les polygones de chaque département seront finalement les géométries regroupées des communes constitutives de chaque département. Le champ Departement sera donc utilisé comme champ de regroupement. Dans le processus, il est également possible de calculer des statistiques sur un ou plusieurs autres champs. Ici, nous choisirons de sommer les populations de chaque commune. Nous disposerons ainsi au final d’un attribut Population dans notre couche des départements qui correspondra bien à la population départementale.
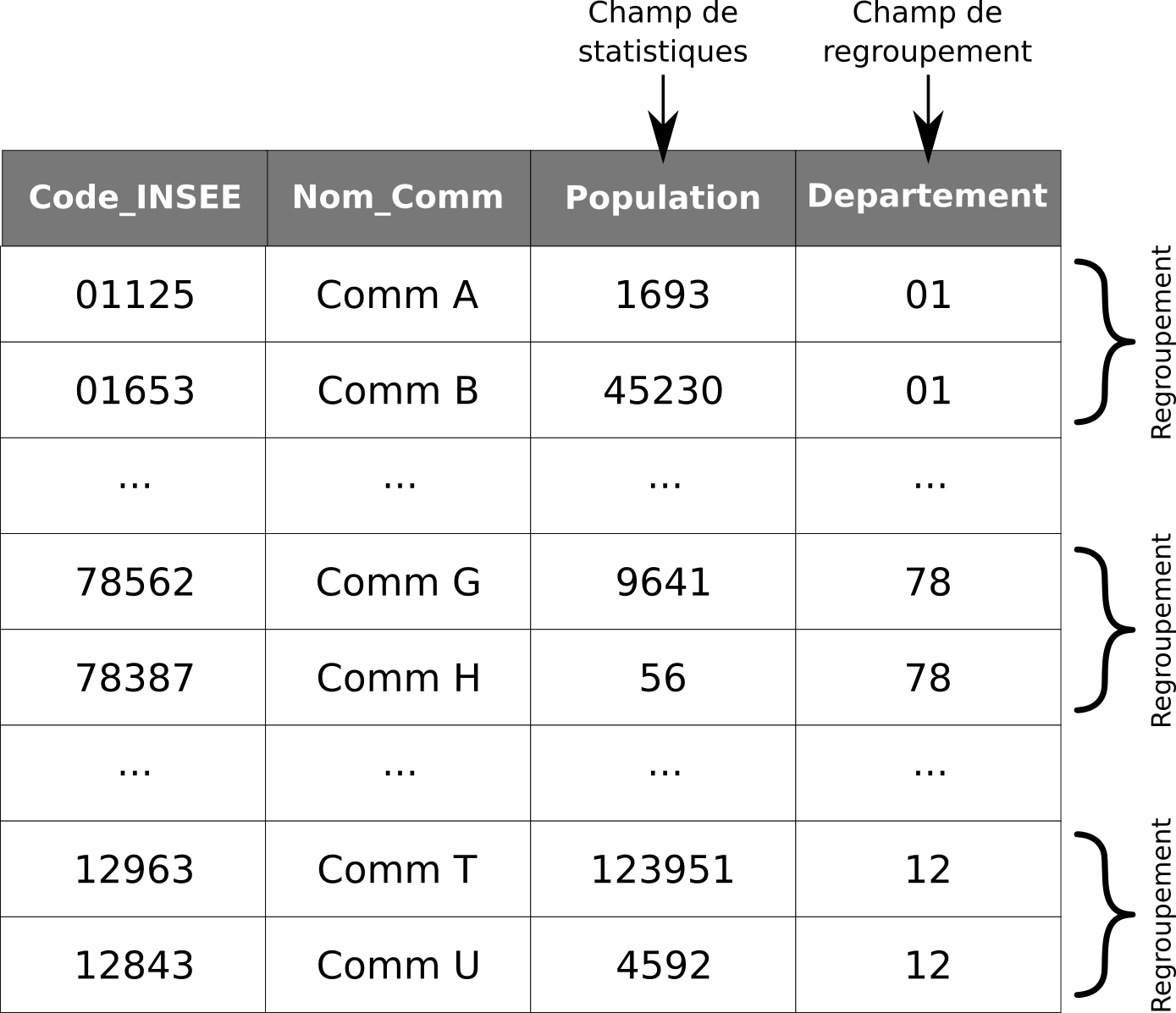
Fig. 228 Regroupement des communes par département afin d’obtenir une couche des départements.
Regrouper des entités dans QGIS
Version de QGIS : 3.22.3
Le regroupement d’entités dans QGIS se fait facilement et permet une grande souplesse. Dans cet exemple, nous allons regrouper les communes d’Île-de-France par département, en calculant en même temps les populations totales par département et les superficies totales. Une fois la couche des communes chargées dans QGIS, nous utilisons le menu . Le menu suivant apparaît (Fig. 229).
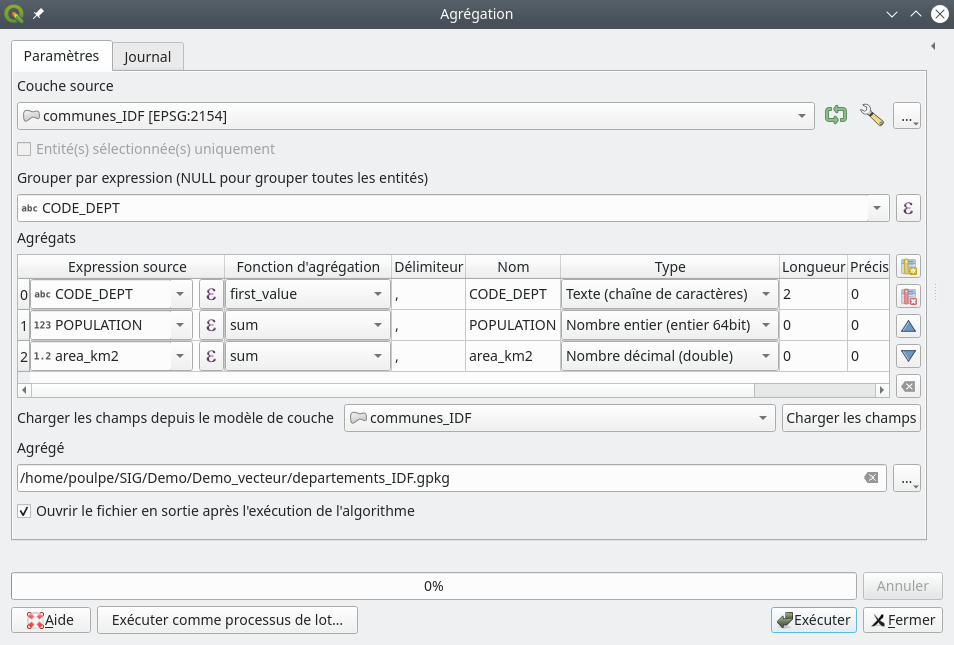
Fig. 229 Regroupement d’entités dans QGIS.
Dans le champ Couche source nous définissons la couche à regrouper, ici communes_IDF.gpkg. Dans le champ Regrouper par expression, nous choisissons le champ sur lequel va s’effectuer le regoupement, ici CODE_Dept. Grâce à l’icône de sélection au bout de la ligne, nous pourrions ne sélectionner que certains départements pour ce regroupement. Notons que si nous laissons cette ligne vide, toutes les entités de la couche seraient regroupées. Dans le panneau Agrégats, tous les champs de la couche sont listés. Nous commençons par enlever les champs qui ne sont pas utiles et/ou pas pertinents. Par exemple le champ contenant le nom de la commune est à enlever car ce ne sera plus une information pertinente sur une couche des départements. Pour supprimer un champ, nous cliquons dessus (il devient bleu) puis nous cliquons sur l’icône Supprimer le champ sélectionné . Une fois que ne restent plus que les champs d’intérêt nous effectuons différents réglages dans ce même panneau Agrégats. Le champ CODE_Dept a été conservé car le code département sera bien un attribut présent dans la table des départements. Dans la colonne Fonction d'agrégation nous sélectionnons first value. Ainsi, pour chaque département, nous retiendrons le premier code rencontré lors du regroupement. Comme toutes les communes d’un même département ont le même code de département le résultat sera bon. Ensuite, pour le champ Population nous choisissons de sommer toutes les populations communales de chaque département rencontré via la Fonction d'agrégation sum (somme). Nous procédons de même pour l’attribut area_km2. Enfin, à la ligne Agrégé nous indiquons un chemin et un nom pour la couche qui sera créée. Puis nous cliquons sur Exécuter.
Astuce
Il est possible d’organiser l’ordre que prendront les champs dans la couche résultat en jouant avec les icônes Déplacer le champ sélectionné vers le haut  et
et Déplacer le champ sélectionné vers le bas  .
.
Une nouvelle couche contenant les polygones des départements apparaît bien. Cette couche possède bien des attributs relatifs au code du département, à la population départementale et à la superficie départementale.
Note
Dans QGIS, il existe un autre menu de regoupement qui se trouve dans le menu Mais cet outil est beaucoup moins pratique que l’outil Agrégation.
Regrouper des entités dans R
Une fois un vecteur chargé dans R, il est possible de regroupement des entités selon un champ tout en calculant une statistique pour un autre champ. Ici, nous allons charger un vecteur des communes d’Île-de-France, qui contient un champ avec les codes des départements CODE_DEPT et un champ de population POPULATION. Nous allons créer un nouvel objet vecteur qui contiendra les départements et leur population totale.
Regrouper des entités avec terra
Version de R : 4.3.1
Version de terra : 1.7.29
Pour faire cette manipulation de regroupement sur un SpatVector de terra, il est nécessaire d’utiliser en plus la librairie tidyterra.
# chargement de tidyterra
library(tidyterra)
# chargement des communes d'IDF
communes_IDF <- terra::vect('communes_IDF.gpkg')
# regroupement selon le code des départements et somme des populations
group_dep <- group_by(communes_IDF, CODE_DEPT) %>% summarize(somme = sum(POPULATION))
Regrouper des entités avec sf
Version de R : 4.3.1
Version de sf : 1.O.12
Pour faire cette manipulation de regroupement sur un objet sf il est nécessaire d’utiliser en plus la librairie dplyr.
# chargement de dplyr
library(dplyr)
# chargement des communes d'Île-de-France
communes_IDF <- sf::st_read('communes_IDF.gpkg')
# regroupement selon le code des départements et somme des populations
dep_group <- communes_IDF %>% group_by(CODE_DEPT) %>% summarise(Pop_Totale = sum(POPULATION))