Auteur : Paul Passy
Licence : 
Classification supervisée d’images satellites
En géographie, un des buts fréquents de la télédétection est de produire une classification de l’usage du sol d’une région à partir d’images satellites. Dans la plupart des cas, nous utilisons une procédure de classification supervisée afin de maîtriser le nombre et la nature des classes qui seront produites. Il existe de nombreuses solutions pour effectuer ce genre de classifications. Nous en détaillerons quelques unes dans cette partie.
Table des matières
Quelques algorithmes
Il existe de très nombreux algorithmes de classification d’images. Ces algorithmes sont plus ou moins complexes et peuvent être mis en pratique par différents outils. Ici, nous présenterons un peu de théorie vulgarisée sur quelques algorithmes couramment rencontrés en classification d’images. Notons que ces techniques de classification ne sont pas propres au monde de l’imagerie mais sont largement utilisés dans le monde de la statistique en général.
Classification par distance minimale
Cet algorithme est aussi connu sous le nom de classification au plus proche voisin. C’est l’algorithme le plus facile à appréhender et à mettre en place. Il est largement répandu dans le monde de la télédétection, bien que maintenant des techniques plus poussées soient plus communément employées.
Comme pour tout processus de classification supervisée, cette technique repose sur une digitalisation manuelle de régions d’entraînement. Chaque région d’entraînement est une région homogène de l’image que l’utilisateur a défini comme étant représentative d’une classe donnée. Ces régions d’entraînement sont aussi connues sous leur appellation en anglais de Region Of Interest (ROI). Pour chaque zone d’entraînement, les valeurs des pixels sous-jacents sont relevées, les moyennes sont calculées, et chaque classe est ainsi caractérisée par une signature radiométrique. L’idée est ensuite d’associer à chaque pixel de l’image qui n’a pas servi comme zone d’entraînement la classe qui lui est le plus proche d’un point de vue radiométrique.
Nous allons illustrer le fonctionnement de cet algorithme sur un cas simplifié. Dans l’exemple, nous souhaitons classifier une image Landsat 8 prise sur le littoral des Bouches-du-Rhône. Cette image se compose de 4 bandes spectrales : Bleu, Vert, Rouge et Proche Infrarouge (PIR). Nous visons une classification en 3 classes : eau, végétation et bâti, respectivement classe 1, 2 et 3. Nous commençons par créer une composition colorée en fausses couleurs (Les compositions colorées en télédétection) qui va nous aider à digitaliser une zone d’entraînement, i.e. un polygone, représentative de chaque classe (Fig. 368).

Fig. 368 Zones d’entraînement des 3 classes. À gauche la composition colorée qui nous sert d’aide d’identification visuelle. À droite, les polygones d’entraînement superposées à chaque bande individuellement.
Une fois les polygones d’entraînement créés, l’algorithme calcule les valeurs de réflectances moyennes dans chaque bande spectrale. Un barycentre est ainsi calculé pour chaque classe. Nous détaillons sur la figure suivante le principe de construction de ce barycentre en prenant en compte seulement la bande du Bleu et du PIR pour des raisons de représentation (Fig. 369).

Fig. 369 Placement des pixels de chaque classe (Classe 1 : Eau, Classe 2 : Végétation, Classe 3 : Bâti.) dans l’espace représenté par les bandes Bleu et PIR (A). Calcul des barycentres de chaque classe (B).
Sur la figure précédente (Fig. 369), chaque pixel de chaque classe a été replacé dans le repère cartésien formé des axes de la bande Bleu, en ordonnée, et de la bande du PIR, en abscisse. La figure est bien sûr simplifiée et les caractéristiques radiométriques de chaque classe sont exacerbées. En bleu, nous retrouvons les pixels de la classe 1. Il y a 9 pixels, ce qui signifie que dans notre exemple, la zone d’entraînement de l’eau recouvre 9 pixels de l’image. Pour chacun de ces 9 pixels, leurs valeurs dans les bandes du Bleu et du PIR sont relevées ce qui permet de replacer ces pixels dans le repère Bleu - PIR (Fig. 369 A). Par exemple, le pixel noté p1 a une valeur de réflectance dans le PIR de 0.02 et dans le Bleu de 0.1. Une fois tous les pixels placés, les barycentres de chaque classe sont calculés (Fig. 369 B). Ce sont maintenant ces barycentres qui vont résumer les classes.
Ces barycentres sont caractérisés par des coordonnées sur les deux axes radiométriques (Fig. 370 A). Pour classifier un pixel quelconque P, l’algorithme va commencer par relever les valeurs de réflectance de ce pixel et le replacer dans le repère contenant les barycentres (Fig. 370 A). Ce pixel va également être caractérisé par deux coordonnées (Xp, Yp).
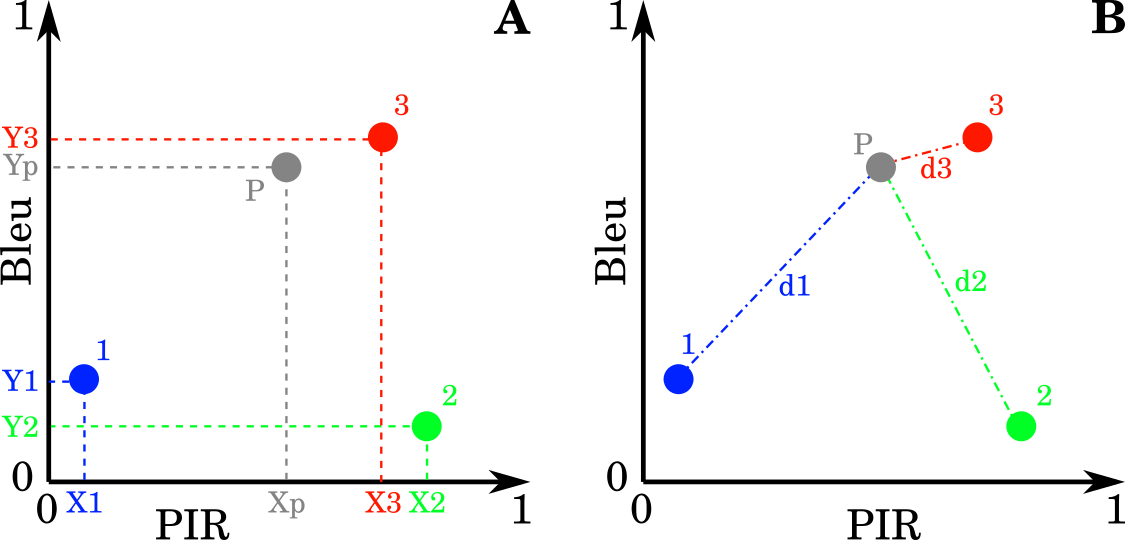
Fig. 370 Les coordonnées de chaque barycentre et du pixel à classifier dans le repère Bleu - PIR (A) et calcul de chaque distance euclidienne (B).
Le but est maintenant de calculer les distances séparant ce pixel à chacun des barycentres. Attention, il ne s’agît pas de distances métriques mais de distances radiométriques, calculées dans notre repère formé des bandes Bleu et PIR (Fig. 370 B). Ces distances sont des distances euclidiennes et se calculent donc facilement selon la formule dédiée. Par exemple pour calculer la distance d1 séparant notre pixel P à classifier du barycentre de la classe 1, l’algorithme utilise la formule suivante.
Une fois toutes les distances calculées, le pixel P est attribué à la classe dont le barycentre est le plus proche. C’est-à-dire à la classe pour laquelle la distance est minimale. Dans notre exemple, P sera attribué à la classe 3, à savoir le bâti.
Pour faciliter l’explication, nous avons considéré un espace à 2 dimensions formées par les bandes du Bleu et du PIR, mais le principe est généralisable à un espace à n dimensions formées de n bandes. Il ne sera juste plus possible de le représenter graphiquement. Ainsi, dans notre cas initial où nous faisons une classification en se basant sur 4 bandes spectrales, chaque barycentre de classe sera repéré selon 4 coordonnées. Le barycentre de la classe 1 aura les coordonnées suivantes (X1, Y1, Z1, T1), où X sera la réflectance de ce barycentre dans la bande du Bleu, Y, dans la bande du Vert, Z dans la bande du Rouge et T dans la bande du PIR. De même un pixel à classifier P sera repéré par (Xp, Yp, Zp, Tp). La distance radiométrique de P au barycentre de la classe 1 sera donc la suivante.
Chaque distance sera calculée de cette façon, et le pixel sera attribué à la classe du barycentre le plus proche.
La classification par distance minimale peut se faire à l’aide du module SCP de QGIS. Elle y est connue sous le nom de Plus proche voisin. Le processus est décrit dans la partie dédiée (Classification supervisée d’images satellites dans QGIS avec SCP).
Création des couches d’entraînement et de validation
Version de QGIS : 3.18.1
Toute classification supervisée d’images satellites nécessite une couche d’entraînement. Cette couche d’entraînement est une couche vecteur de type polygones où chaque polygone est représentatif d’une classe. Les polygones doivent être suffisamment grands pour prendre en compte l’hétérogénéité de chaque classe mais suffisamment homogènes pour ne représenter qu’une classe.
Avertissement
Le module SCP a une procédure de digitalisation de couche d’entraînement propre. Si vous utilisez ce module, cette section n’est pas utile, rendez-vous directement ici : Classification supervisée d’images satellites dans QGIS avec SCP.
Définition des classes
Le principe général est de commencer par définir les classes souhaitées au final, par exemple zone arborée, eau, sol nu, bâti… Une fois ces classes définies, nous repérons visuellement sur l’image satellite des ensembles de pixels représentatifs de ces classes. Nous pouvons nous servir des compositions colorées pour mieux identifier ces groupes de pixels. Ensuite, nous créons une couche vecteur de type polygones et nous digitalisons manuellement des polygones représentatifs de ces classes. Ces polygones sont parfois connues sous le nom de ROI pour Region Of Interest. Pour chaque classe, nous devons associer plusieurs polygones afin de nous assurer de la représentativité des polygones. Au final, c’est cette couche vecteur qui servira d’entraînement à la classification supervisée.
Dans l’exemple présenté ici, nous allons digitaliser une couche d’entraînement en 7 classes pour classifier une image Landsat TM du Caire prise le 13 juillet 2011. Les 7 classes sont présentées dans le tableau suivant.
ID classe |
Label classe |
|---|---|
1 |
Eau |
2 |
Végétation inondée |
3 |
Végétation dense |
4 |
Sol nu sableux |
5 |
Sol nu rocheux |
6 |
Bâti dense |
7 |
Bâti diffus |
Chaque classe doit être identifiée par un identifiant au format Entier (Integer). En effet, les algorithmes de classification ne travaillent que sur des données numériques. Le label textuel est simplement là pour rendre les classes plus facilement identifiables par l’utilisateur.
La première chose à faire est de repérer sur l’images des zones représentatives de ces classes (Fig. 371). Une composition colorée peut nous aider (Composition colorée avec QGIS).
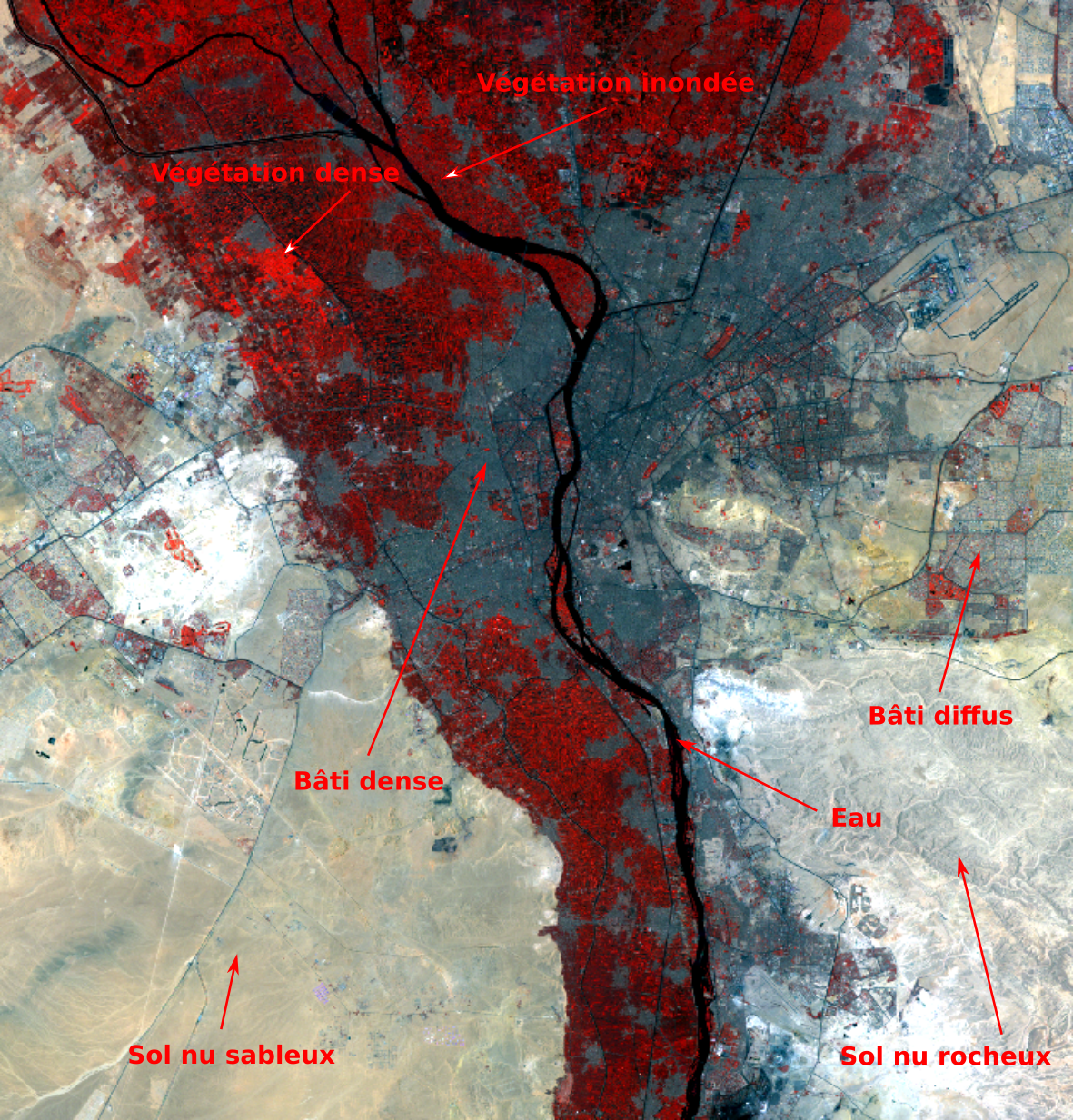
Fig. 371 Repérage de zones représentatives de chaque classe.
Couche d’entraînement
Création de la couche
La digitalisation peut se faire avec QGIS (Digitalisation), ce que nous ferons ici. Nous commençons par créer et paramétrer la couche vecteur. Nous allons dans le menu Le menu de création de couche apparaît (Fig. 372).

Fig. 372 Initialisation de la couche d’entraînement.
À la ligne Base de données, nous indiquons le chemin et le nom de la couche que nous allons créer, ici train_7.gpkg. Le Nom de la table se remplit automatiquement mais nous pouvons le changer si nous le souhaitons. Pour le Type de géométrie nous spécifions Polygone. Ensuite il faut bien faire attention de définir le SCR de cette couche d’entraînement correctement. Le SCR doit être le même que celui de l’image satellite à classifier. Ici, notre image est en WGS84 / UTM Zone 36 N (EPSG 32636). Le SCR est modifiable en cliquant sur l’icône adjacente  . Dans le panneau
. Dans le panneau Nouveau champ, nous ajoutons deux champs. Nous nommons le premier id_classe de type Nombre entier et le second label_classe de type Donnée texte. Puis nous cliquons sur OK. Notre nouvelle couche, vide pour le moment, apparaît bien dans le panneau des couches.
Définition d’un formulaire
Avant de créer nos polygones d’entraînement nous allons définir un formulaire qui va nous faciliter la création de nos polygones. Cette étape n’est pas indispensable, vous pouvez la passer et vous rendre ici Digitalisation des polygones si vous le désirez. Dans le panneau des couches, nous faisons un clic droit sur notre couche d’entraînement et allons dans . Le menu du formulaire s’ouvre (Fig. 373).
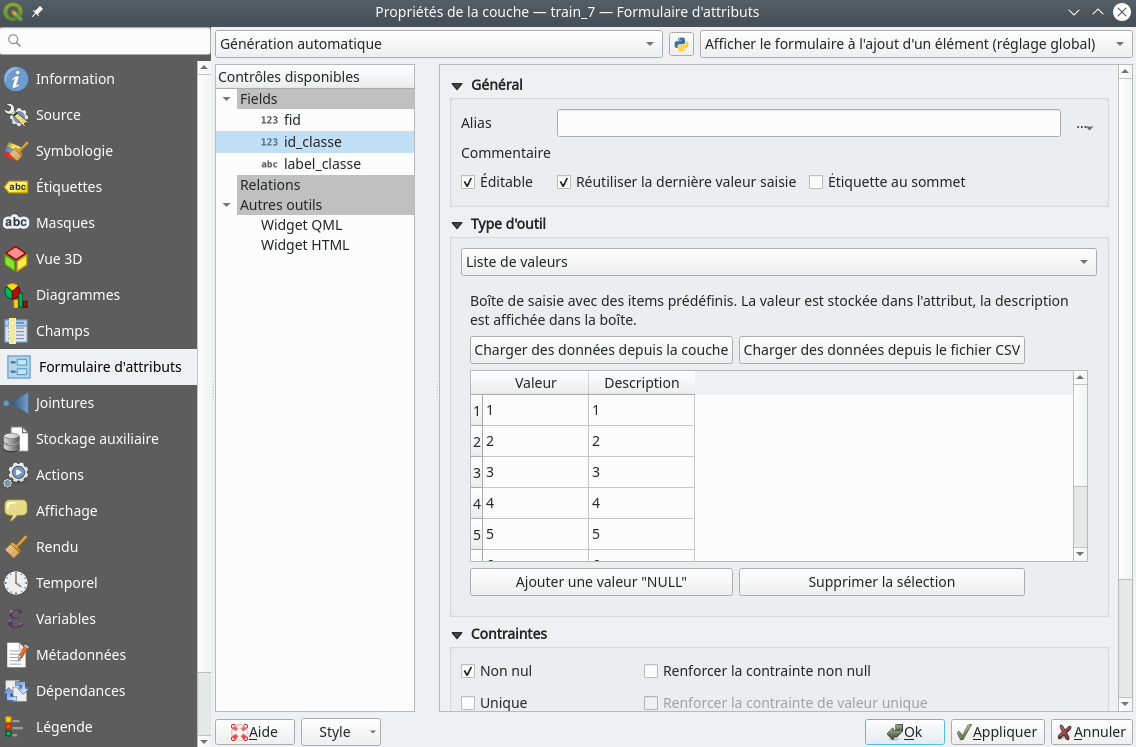
Fig. 373 Définition d’un formulaire de saisie.
Dans le panneau Contrôles disponibles, nous sélectionnons le champ id_classe pour lui adjoindre un formulaire. Une fois ce champ sélectionné, il est alors surligné en bleu, dans le panneau Général, nous cochons la case Éditable et Réutiliser la dernière valeur saisie. Dans le panneau Type d'outils, dans le menu déroulant nous choisissons Liste de valeurs. Ainsi, nous n’aurons pas à entrer à la main les identifiants des classes mais nous les choisirons parmi une liste de valeurs. Cela nous évitera les fautes de frappe. Dans la zone d’édition qui suit nous ajoutons à la colonne Valeur 7 lignes avec des valeurs de 1 à 7. Enfin, dans le panneau Contraintes nous cochons la case Non nul pour préciser que cette colonne d’identifiant doit obligatoirement être renseignée.
Nous procédons ensuite de même pour le champ label_classe en le sélectionnant dans le panneau Contrôles disponibles. Nous cochons la case Éditable et Réutiliser la dernière valeur saisie. Nous sélectionnons encore Liste de valeurs et nous remplissons les valeurs que peuvent prendre ce champ. Ici ce ne sont plus des identifiants de 1 à 7 mais les labels textuels des classes (Fig. 374). Puis nous cochons aussi la case Non nul. Nous pouvons maintenant passer à la digitalisation proprement dite.
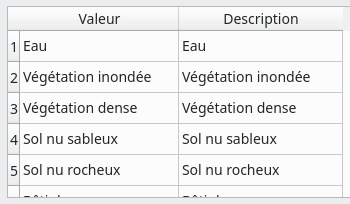
Fig. 374 Définition d’un formulaire de saisie pour les labels de classes.
Digitalisation des polygones
Nous allons commencer par digitaliser un premier polygone représentatif de la classe Eau. Nous zoomons quelque part sur le Nil, nous sélectionnons notre couche d’entraînement dans le panneau des couches et nous la rendons éditable en cliquant sur l’icône Basculer en mode édition  dans la barre d’outils de digitalisation. Nous sélectionnons ensuite l’outil de création d’entités en cliquant sur l’icône
dans la barre d’outils de digitalisation. Nous sélectionnons ensuite l’outil de création d’entités en cliquant sur l’icône Ajouter une entité polygonale  . Le curseur devient alors une sorte de cible. Il suffit alors de digitaliser notre polygone d’entraînement par une série de clics gauches terminés par un clic droit pour fermer le polygone. Une fenêtre s’ouvre pour remplir les champs associés à cette entité. Comme nous avons défini un formulaire, il nous propose les premières valeurs des listes définies, à savoir 1 pour le champ id_classe et Eau pour le champ label_classe (Fig. 375). Comme nous venons de digitaliser un polygone d’eau nous laissons ces valeurs.
. Le curseur devient alors une sorte de cible. Il suffit alors de digitaliser notre polygone d’entraînement par une série de clics gauches terminés par un clic droit pour fermer le polygone. Une fenêtre s’ouvre pour remplir les champs associés à cette entité. Comme nous avons défini un formulaire, il nous propose les premières valeurs des listes définies, à savoir 1 pour le champ id_classe et Eau pour le champ label_classe (Fig. 375). Comme nous venons de digitaliser un polygone d’eau nous laissons ces valeurs.
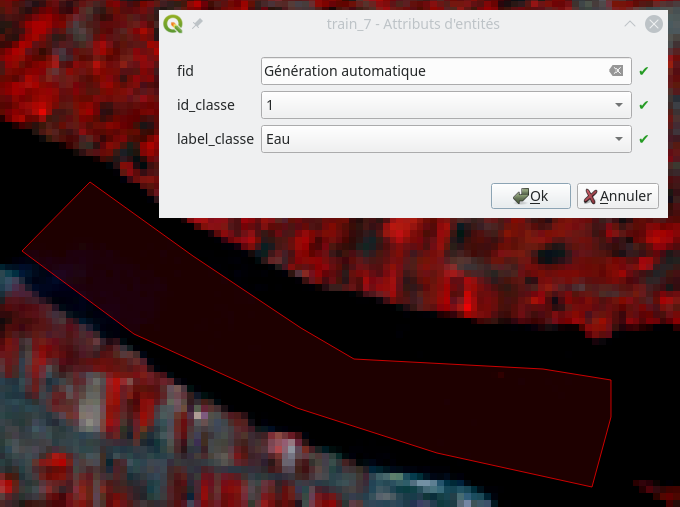
Fig. 375 Digitalisation d’un polygone d”Eau et formulaire de remplissage des champs associés.
Nous recommençons la manipulation pour avoir 4 autres polygones représentatifs de cette classe Eau. Comme le formulaire a été réglé à Réutiliser les dernières valeurs saisies, les identifiant et label de la classe Eau sont automatiquement proposés.
Note
Pensez à régulièrement enregistrer votre couche en cliquant sur l’icône Enregistrer les modifications de la couche  .
.
Nous procédons ensuite de même pour les 6 autres classes : végétation inondée, végétation dense, sol nu sableux, sol nu rocheux, bâti dense et bâti diffus. Nous pouvons digitaliser 5 polygones par classe (Fig. 376). Notez que l’intérêt du formulaire qui nous facilite la tâche de remplissage de la table attributaire. Il faut simplement avoir bien en tête les identifiants numériques de chaque classe. Lorsque tous les polygones sont digitalisés, nous quittons le mode édition de la couche en recliquant sur l’icône d’édition .
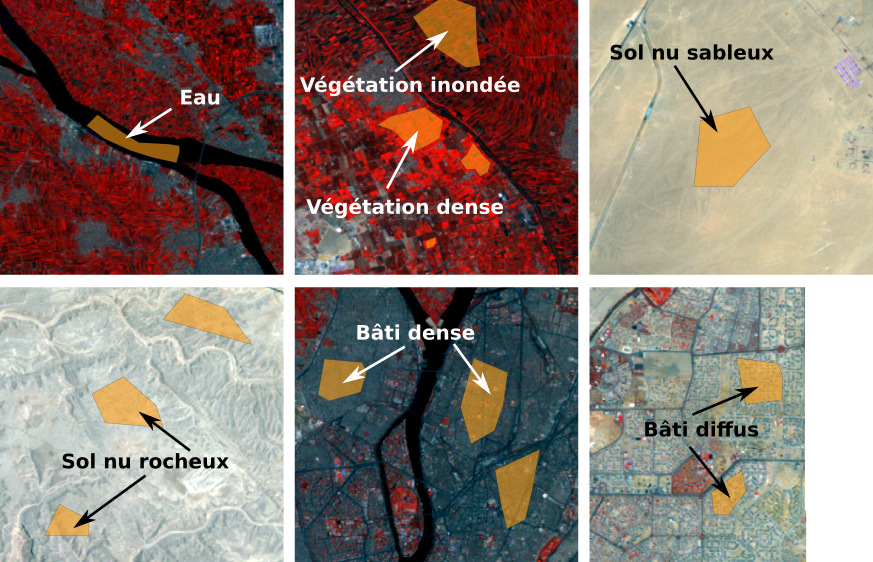
Fig. 376 Polygones d’entraînement des différentes classes.
Couche de validation
Les classifications supervisées doivent toujours être accompagnées d’une validation, autrement dit d’un ensemble d’indicateurs numériques renseignant sur la qualité de la classification. Ce calcul de qualité fait intervenir une couche dite de validation. Finalement cette couche est en tous points semblable à la couche d’entraînement avec des polygones représentatifs de chaque classe. La seule différence est que les polygones ne sont pas digitalisés aux mêmes endroits. Dans notre cas nous pouvons nommer cette couche valid_7.gpkg. Nous ne sommes pas obligés de digitaliser autant de polygones, nous pouvons nous contenter de 3 polygones par classe. Pour les aspects pratiques liés à la digitalisation, se référer à la section dédiée : Digitalisation des polygones.
Note
Combien de polygones de contrôle soit-on digitaliser pour chaque classe ? Il n’y a pas vraiment de réponse absolue. Il en faut plusieurs… Trois, cinq, plus, selon l’utilisateur. Ici, nous en prendrons trois par classe. Certains auteurs proposent des méthodes rigoureuses pour choisir ce nombre (Olofsson et al., 2014 par exemple).
Il est important de digitaliser les polygones de contrôle non pas en se basant sur le raster de classification, ce qui serait un non sens méthodologique mais en se basant sur une interprétation visuelle d’une composition colorée (Fig. 377) ou sur l’interprétation d’une image à plus haute définition.
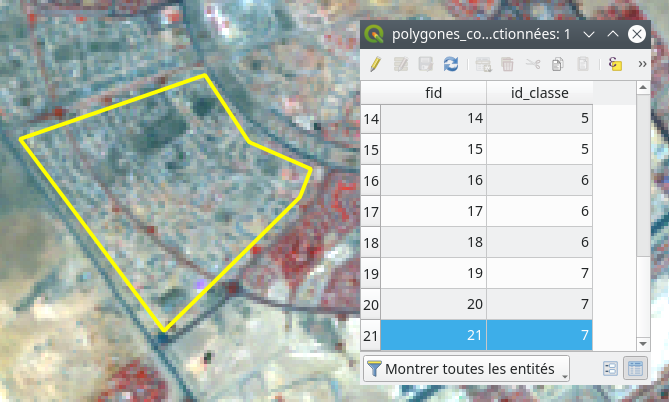
Fig. 377 Un polygone de validation de Bâti diffus et la table attributaire associée.
Classification supervisée d’images satellites dans QGIS avec SCP
Version de QGIS : 3.24.1
Version de SCP : 7.10.6
Dans cette partie nous allons voir comment effecteur une classification supervisée d’images satellites en utilisant le module SCP (Semi-Automatic Classification Plugin) de QGIS. Comme dit dans la partie de présentation des outils, ce module propose de très riches fonctionnalités de classification et de traitements liés à ces classifications.
Ici, nous allons prendre l’exemple d’une classification de l’occupation du sol de la région du Caire en Égypte à partir d’une image Landsat 5 TM du 13 juillet 2011.
Avertissement
Le module SCP évolue très vite, de nouvelles mises à jour sont distribuées régulièrement. Lors de ces mises à jour, les fonctionnalités évoluent et l’interface également. La trame général de ce qui est présenté ici ne devrait pas changer mais les détails, notamment les endroits où cliquer et le nom des menus peut évoluer.
Définition du jeu de bandes à classifier
Toute classification s’appuie sur un, ou plus souvent plusieurs rasters à classifier. Ces rasters sont souvent des bandes spectrales mais peuvent également être des indices radiométriques comme des NDVI ou autres. Ici, nous souhaitons classifier les bandes 1, 2, 3, 4, 5 et 7 d’une image Landsat TM afin d’en dériver une occupation du sol. La première chose à faire est de charger ces bandes dans QGIS.
Une fois ces bandes chargées, nous spécifions à SCP que ce sont ces bandes que nous souhaitons classifier. En terminologie SCP, nous allons définir ces bandes comme étant le Jeu de bandes (Band set) à classifier. Pour cela, nous allons dans le menu . La fenêtre suivante apparaît (Fig. 378).
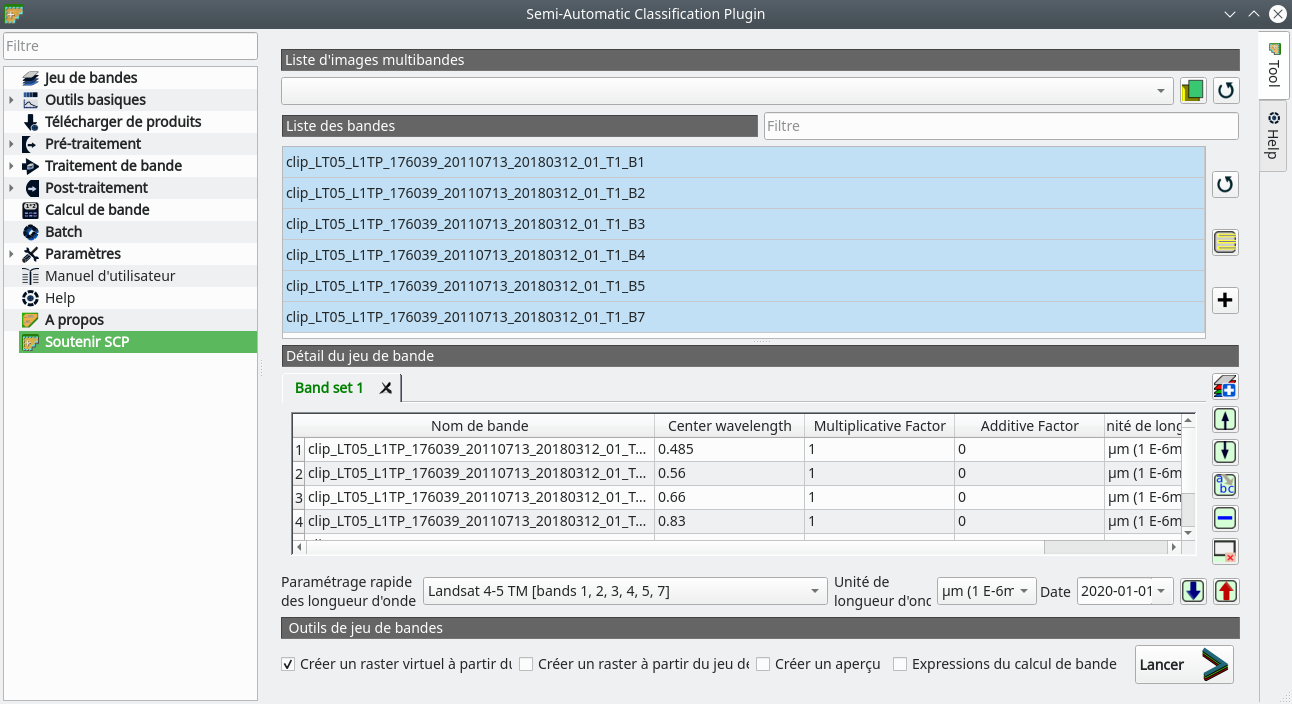
Fig. 378 Définition du jeu de bandes dans SCP.
En premier lieu, nous listons la liste des bandes chargées dans QGIS dans le panneau Liste des bandes en cliquant sur l’icône  . Une fois les bandes listées, nous sélectionnons celles à ajouter à notre jeu de bandes. Ici nous sélectionnons donc toutes nos bandes. Nous les ajoutons à notre jeu de bandes en cliquant sur l’icône
. Une fois les bandes listées, nous sélectionnons celles à ajouter à notre jeu de bandes. Ici nous sélectionnons donc toutes nos bandes. Nous les ajoutons à notre jeu de bandes en cliquant sur l’icône  Les bandes apparaissent maintenant dans le panneau
Les bandes apparaissent maintenant dans le panneau Détail du jeu de bande comme étant le Band set 1. Il est possible de spécifier à SCP que nous travaillons sur des images Landsat 5 TM, en choisissant ce capteur dans le menu déroulant Paramétrage rapide des longueurs d'onde. Grâce à ça, une longueur d’onde centrale est définie pour chaque bande. Il est ensuite possible de créer un raster virtuel à partir ce jeu de bandes en cochant la case Créer un raster virtuel à partir du jeu de bandes dans le bas de la fenêtre. Ensuite, nous cliquons sur Lancer. Nous spécifions un chemin pour la création du raster virtuel et même si nous avons l’impression que rien ne se passe, notre jeu de bandes est créé.
Note
L’interface de SCP étant touffue, il se peut que le nom des menus n’apparaisse pas en entier, notamment sur un petit écran.
Nous avons maintenant notre jeu de bandes bien défini et un raster virtuel ouvert dans QGIS. À partir de ce raster virtuel, nous pouvons faire une composition colorée en fausses couleurs (PIR, Vert, Bleu) qui va nous permettre de bien identifier visuellement l’occupation du sol.
Définition des classes d’occupation du sol
Comme il s’agît d’une classification supervisée, nous devons au préalable définir quelles occupations du sol nous souhaitons obtenir à partir de cette image. Cette étape se fait en fonction de notre problématique, de notre connaissance du terrain et de l’observation de l’image.
Il est à noter que SCP oblige l’utilisateur à définir deux niveaux de classification. Un niveau méta-classe et un niveau classe. Une méta-classe est par exemple Végétation qui regrouperait des classes comme Forêt de feuillus, Forêts de conifères, Prairies … Ou une méta-classe Bâti subdivisée en classes Bâti dense, Bâti diffus, Routes … Si nous ne souhaitons pas de hiérarchie il suffit de ne mettre qu’une seule classe par méta-classe.
Chaque méta-classe et chaque classe posséderont un label ainsi qu’un identifiant numérique entier. L’identifiant de type entier est obligatoire car c’est sur celui-ci que l’algorithme de classification va travailler. Dans notre exemple, nous allons classifier notre image comme présenté dans le tableau suivant.
ID méta-classe |
Label méta-classe |
ID classe |
Label classe |
|---|---|---|---|
1 |
Eau |
1 |
Eau |
2 |
Végétation |
2 |
Végétation inondée |
2 |
Végétation |
3 |
Végétation dense |
3 |
Sol nu |
4 |
Sol nu sableux |
3 |
Sol nu |
5 |
Sol nu rocheux |
4 |
Bâti |
6 |
Bâti dense |
4 |
Bâti |
7 |
Bâti diffus |
Nous aurons ainsi 4 méta-classes subdivisées en 7 classes. Seule la méta-classe Eau ne sera pas subdivisée. Une fois cette liste effectuée, il faut repérer visuellement sur l’image des zones représentatives de chacune de ces classes (Fig. 379).
Fig. 379 Repérage de zones représentatives de chaque classe.
Digitalisation des polygones d’apprentissage
Comme toute classification supervisée, il nous faut délimiter des polygones d’apprentissage correspondant aux classes souhaitées. Pour chaque classe nous allons digitaliser trois polygones représentatifs. Dans un processus de classification supervisée, ces polygones sont souvent connus sous l’acronyme anglais de ROI pour Region Of Interest (Région d’Intérêt).
Note
Combien de polygones d’apprentissage faut-il digitaliser pour chaque classe ? Il n’y a pas de réponse absolue, entre 3 et plus selon votre zone d’étude.
Avant de digitaliser notre premier ROI (nous commençons par la classe Eau par exemple), nous indiquons à SCP un chemin et un nom sous lequel nous allons sauver notre couches de polygones d’apprentissage. Pour cela, nous nous plaçons dans le panneau SCP situé en bas à gauche de l’écran de QGIS et nous cliquons sur Créer une nouvelle donnée d'entraînement  dans l’onglet
dans l’onglet Entrée données d’entraînement. Nous pouvons nommer ce fichier train_2011. Ce fichier sera sauvé au format .scp, propre à ce module. Le chemin se met à jour dans le champ correspondant (Fig. 380).
Avertissement
Dans SCP la création des polygones d’apprentissage est extrêmement procédurière. Il faut bien s’imprégner des étapes.
Nous devons ensuite indiquer à SCP que nous allons digitaliser la classe Eau qui se trouve dans la méta-classe Eau. Pour cela, toujours dans le panneau SCP, nous allons dans l’onglet Entrée données d’entraînement. Nous spécifions, dans le bas du panneau, que nous allons digitaliser un ROI appartenant à la méta-classe 1 (MC ID 1) dont le label est Eau (Nom de MC Eau) et qui sera plus précisément représentatif de la classe 1 (C ID 1) dont le label est Eau (Nom de C Eau) (Fig. 380).
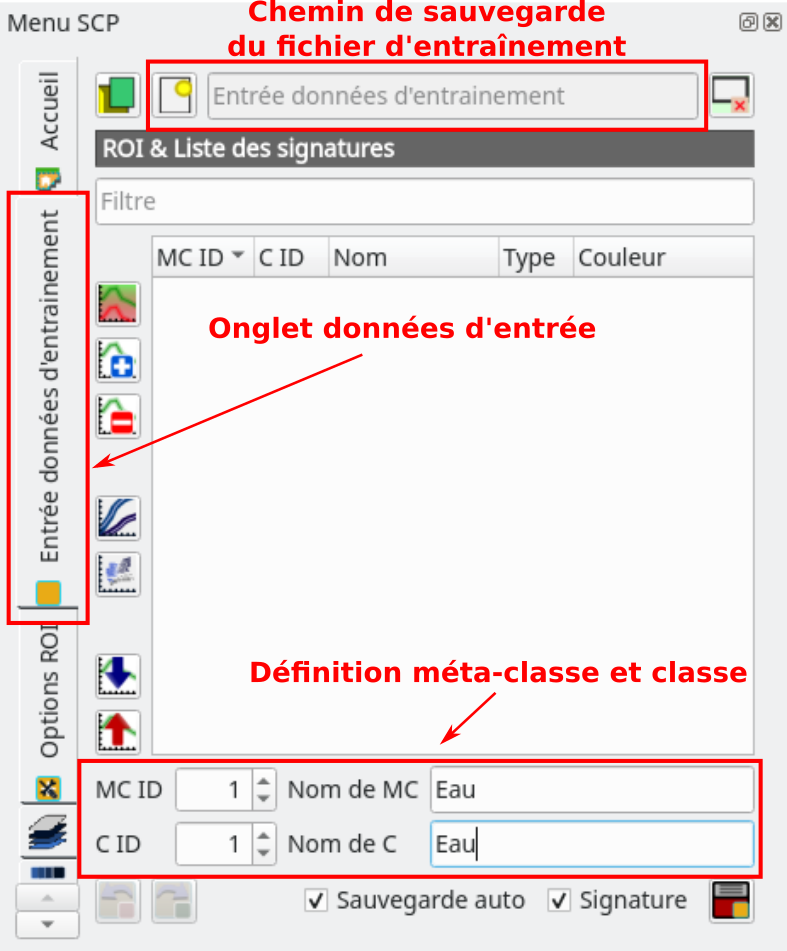
Fig. 380 Définition de la méta-classe et de la classe à digitaliser.
Dans SCP, il existe deux façons de digitaliser des ROI. La première est classique et se fait manuellement. Nous zoomons fortement sur une zone en eau et nous sélectionnons l’outil Create a ROI polygon  qui se trouve dans la
qui se trouve dans la SCP Working Toolbar. Une fois cet outil sélectionné, le curseur se change en croix. Au-dessus du curseur, la valeur de NDVI du pixel sous-jacent s’affiche. Nous allons digitaliser un polygone représentatif de l’eau. Ce polygone doit être suffisamment petit pour être homogène mais suffisamment grand pour rassembler une certaine quantité de pixels (quelques dizaines). La digitalisation se fait classiquement par une série de clics gauches suivie d’un clic droit pour fermer le polygone (Fig. 381).

Fig. 381 ROI manuel pour la classe Eau.
Astuce
Si le polygone n’est pas satisfaisant, il est possible de l’annuler complètement en faisant Ctrl + z.
Une fois ce polygone digitalisé, il est nécessaire de l’enregistrer en cliquant sur l’icône  qui se trouve en bas à droite du panneau SCP. Deux nouvelles lignes apparaissent dans le panneau. Une pour la méta-classe, en gras, et une pour la classe (Fig. 382). Nous pouvons changer la couleur de la méta-classe et de la classe en double cliquant sur l’applat coloré.
qui se trouve en bas à droite du panneau SCP. Deux nouvelles lignes apparaissent dans le panneau. Une pour la méta-classe, en gras, et une pour la classe (Fig. 382). Nous pouvons changer la couleur de la méta-classe et de la classe en double cliquant sur l’applat coloré.
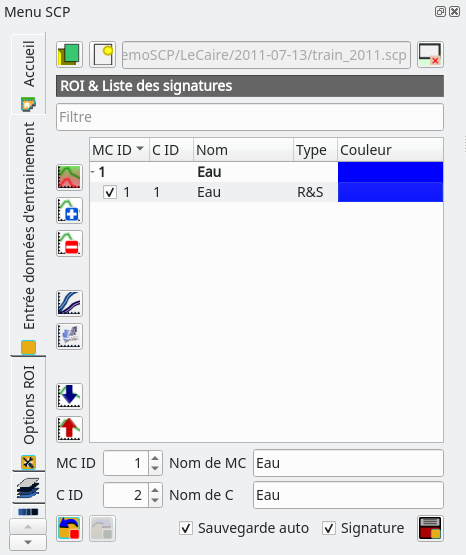
Fig. 382 Mise à jour des classes dans le panneau SCP.
Nous allons maintenant digitaliser un deuxième polygone pour la classe Eau, mais de façon automatique. Nous zoomons sur une autre zone en eau. Avant la digitalisation, il faut s’assurer que nous sommes toujours dans la méta-classe Eau et que l’identifiant de classe a été incrémenté (Fig. 383).
Avertissement
À ce niveau, même si nous digitalisons un polygone appartenant à la même classe, il faut lui mettre un identifiant différent. Nous ferons une fusion des polygones plus tard.

Fig. 383 Classe incrémentée.
Pour capturer un ROI automatique nous nous servons de l’outil Activate ROI pointer  de la SCP Working Toolbar. Le curseur se remet en croix et il suffit de cliquer sur un pixel représentatif de notre zone. Les pixels similaires les plus proches seront automatiquement capturés (Fig. 384). Il est possible de régler la distance minimale et maximale de ce ROI automatique ainsi que du niveau d’hétérogénéité autorisée au sein du ROI. Ce réglage se fait avec les champs numériques
de la SCP Working Toolbar. Le curseur se remet en croix et il suffit de cliquer sur un pixel représentatif de notre zone. Les pixels similaires les plus proches seront automatiquement capturés (Fig. 384). Il est possible de régler la distance minimale et maximale de ce ROI automatique ainsi que du niveau d’hétérogénéité autorisée au sein du ROI. Ce réglage se fait avec les champs numériques Dist, Min et Max de la même barre d’outils.
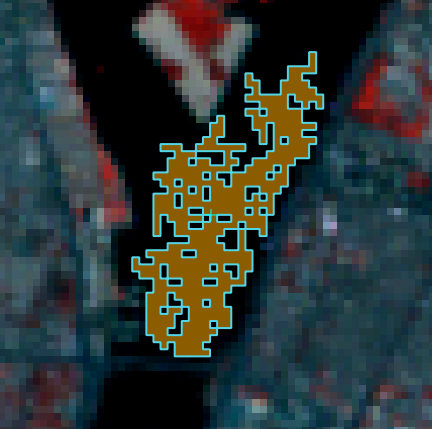
Fig. 384 Création automatique de ROI pour la classe Eau.
Une fois ce ROI automatique créé, nous l’enregistrons comme précédemment. Une troisième ligne apparaît dans le panneau SCP. Nous recommençons la manipulation pour un troisième polygone d’eau pris ailleurs sur l’image.
À ce stade, nous disposons de 4 lignes dans le panneau SCP, une pour la méta-classe et 3 pour les 3 polygones d’eau. La prochaine étape va être de fusionner les signatures spectrales de nos 3 polygones d’eau afin d’obtenir une signature spectrale moyenne de la classe Eau. Avant cette fusion, nous pouvons vérifier que nos trois polygones sont bien similaires d’un point de vue radiométrique. SCP propose un outil simple pour tracer les signatures spectrales de ces polygones. Nous sélectionnons les 3 lignes correspondantes à nos 3 polygones dans le panneau SCP et nous cliquons sur l’icône 
Ajouter les signatures spectrales surlignées au graphique (Fig. 385).
Fig. 385 Calcul des signatures spectrales des polygones sélectionnés.
Les signatures spectrales apparaissent dans une nouvelle fenêtre (Fig. 386). Sur ce graphique, nous retrouvons autant de lignes que de polygones sélectionnés. En abscisse nous avons les longueurs d’ondes et en ordonnées les niveaux d’énergies réfléchies. Les lignes verticales pointillées correspondent aux bandes spectrales du jeu de bandes, ici ce sont donc les bandes Landsat TM. Pour chaque signature est indiquée son enveloppe min - max. Ici, nous souhaitons avoir des polygones représentatifs d’une seule classe ; nous souhaitons donc que nos signatures soient le plus proches possibles (ce qui est bien le cas).
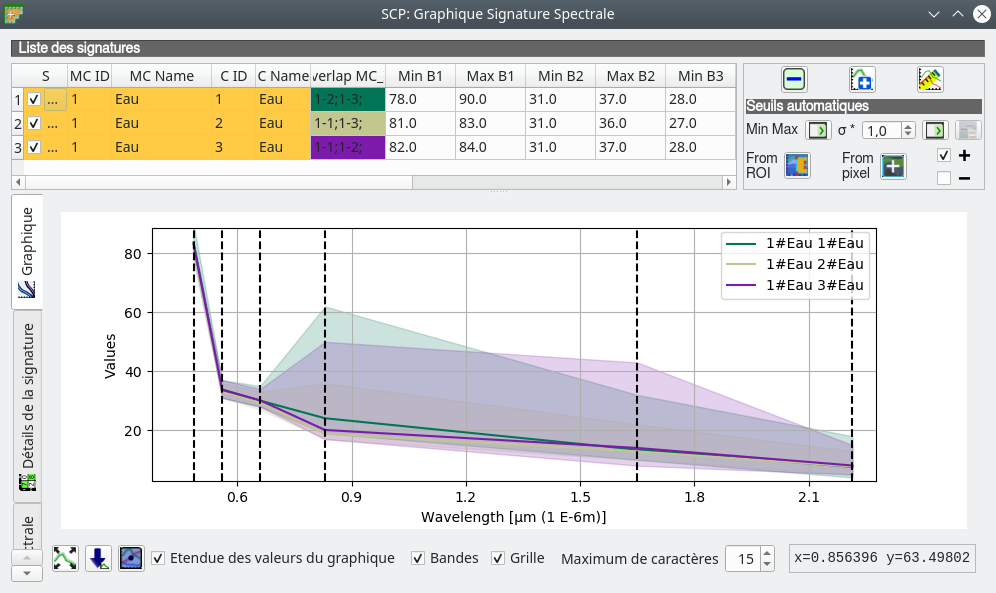
Fig. 386 Signatures spectrales des polygones sélectionnés.
Note
Les signatures spectrales sont calculées sur les bandes spectrales définies dans le Jeu de bandes.
Si nous sommes satisfaits de nos signatures nous pouvons maintenant les fusionner afin d’obtenir une signature moyenne (représentative) de notre classe Eau. Pour cela nous sélectionnons nos 3 lignes à fusionner (dans le Menu SCP dans la fenêtre principal de QGIS) et nous sélectionnons l’outil Fusionner les signatures spectrales surlignées  . Une quatrième ligne intitulée merged_eau est apparue. Nous pouvons maintenant supprimer les 3 lignes initiales et ne considérer que la signature issue de la fusion. Pour effectuer cette suppression, nous sélectionnons les 3 lignes à supprimer et nous cliquons sur
. Une quatrième ligne intitulée merged_eau est apparue. Nous pouvons maintenant supprimer les 3 lignes initiales et ne considérer que la signature issue de la fusion. Pour effectuer cette suppression, nous sélectionnons les 3 lignes à supprimer et nous cliquons sur Supprimer les éléments surlignés  . Nous pouvons changer la couleur de cette classe fusionnée (Fig. 387).
. Nous pouvons changer la couleur de cette classe fusionnée (Fig. 387).
Fig. 387 La seconde ligne correspond à la signature fusionnée. Remarquez bien son identifiant à 1 et son label Eau.
Nous pouvons maintenant passer à la digitalisation des ROI de la deuxième méta-classe Végétation, en commençant par la classe Végétation inondée. Nous commençons par définir dans le panneau SCP une méta-classe 2 ayant pour label Végétation et une classe 2 avec pour label Végétation inondée (Fig. 388).

Fig. 388 Définition de la deuxième méta-classe et de sa première classe.
Nous digitalisons ensuite manuellement ou automatiquement les 3 polygones d’apprentissage de la classe Végétation inondée de la même manière qu’effectuée pour la classe Eau. Puis nous répétons l’opération pour la seconde classe de végétation (Végétation dense) puis pour toutes les autres méta-classes et classes (Fig. 389).
Avertissement
Pensez bien à enregistrer le polygone après chaque digitalisation de polygone en cliquant sur l’icône .

Fig. 389 Exemple de ROI pour les autres classes.
Avertissement
Attention de bien définir chaque nouvelle méta-classe à chaque fois qu’on s’attaque à une nouvelle méta-classe et à bien régler à postériori les identifiants et labels de classes issues des fusions de signatures.
À ce stade nous disposons de polygones d’apprentissage pour chacune de nos classes (Fig. 390).
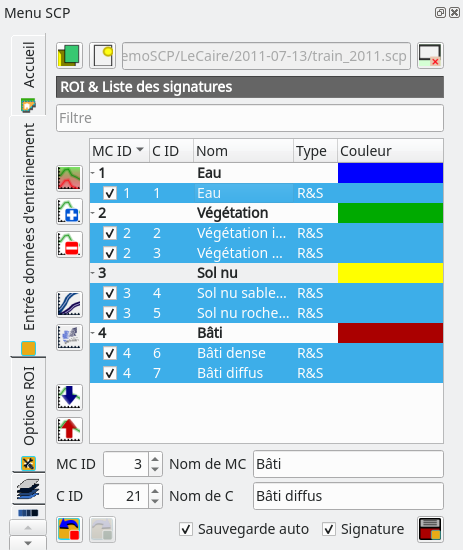
Fig. 390 ROI finaux.
Contrôle des polygones d’apprentissage
Avec SCP il est possible tracer les signatures spectrales de toutes ces classes afin de vérifier qu’elles s’individualisent bien les unes des autres. Nous sélectionnons les classes à tracer dans le panneau SCP et nous cliquons sur l’icône Ajouter les signatures spectrales au graphique  (Fig. 391).
(Fig. 391).
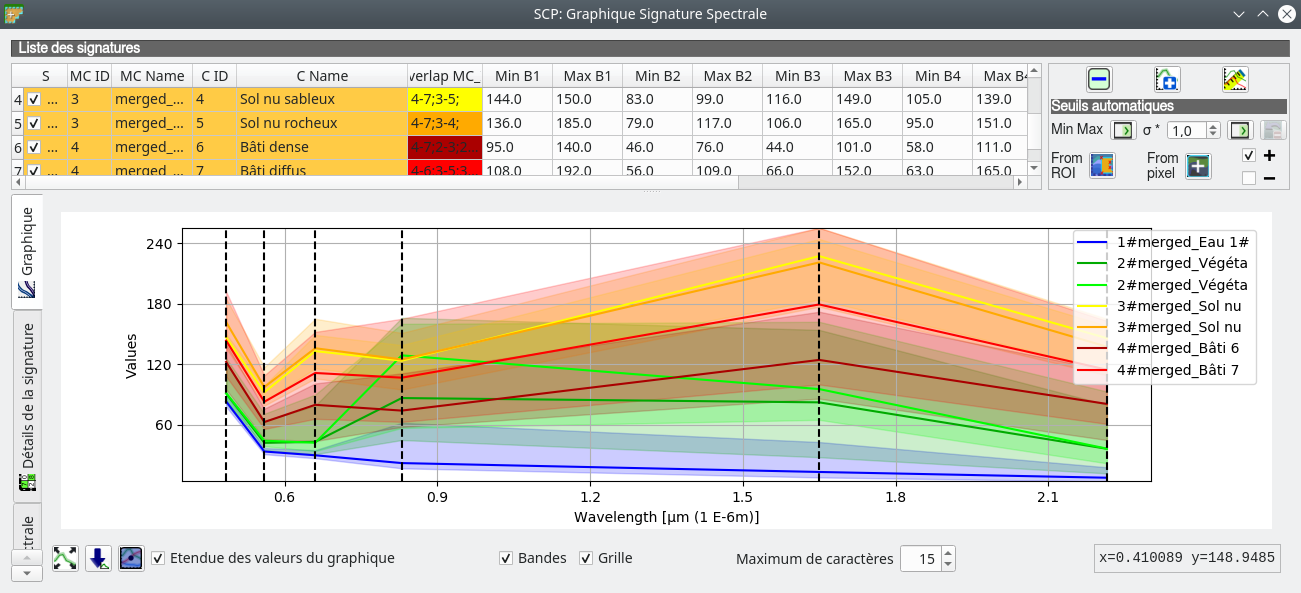
Fig. 391 Signatures spectrales des ROI.
Nous retrouvons les signatures spectrales de nos 7 classes, les couleurs sont les mêmes que celles définies dans le panneau SCP. Les lignes pointillées correspondent aux bandes Landsat TM. Par exemple, pour la classe Eau, nous retrouvons bien la signature typique de l’eau avec un léger pic dans le domaine du Bleu et une forte décroissance jusqu’à des valeurs quasi nulles dans l’infrarouge. De même, la végétation présente bien le pic caractéristique dans le proche infrarouge. Nous pouvons constater que les signatures spectrales des deux classes de sol nu sont très proches, il y a donc un fort risque de confusion entre ces deux classes dans la classification finale.
Il est possible de quantifier la séparabilité des classes via l’outil Calculer les distances spectrales  qui se trouve sur la partie droite de la fenêtre des graphiques. Les similarités entre classes sont calculées selon quatre critères différents. Pour des détails sur ces critères, se référer à la documentation du module SCP. Les distances spectrales sont calculées pour tous les couples de classes possibles. Lorsqu’une métrique indique une similarité entre deux classes, cette métrique est affichée en rouge (Fig. 392).
qui se trouve sur la partie droite de la fenêtre des graphiques. Les similarités entre classes sont calculées selon quatre critères différents. Pour des détails sur ces critères, se référer à la documentation du module SCP. Les distances spectrales sont calculées pour tous les couples de classes possibles. Lorsqu’une métrique indique une similarité entre deux classes, cette métrique est affichée en rouge (Fig. 392).
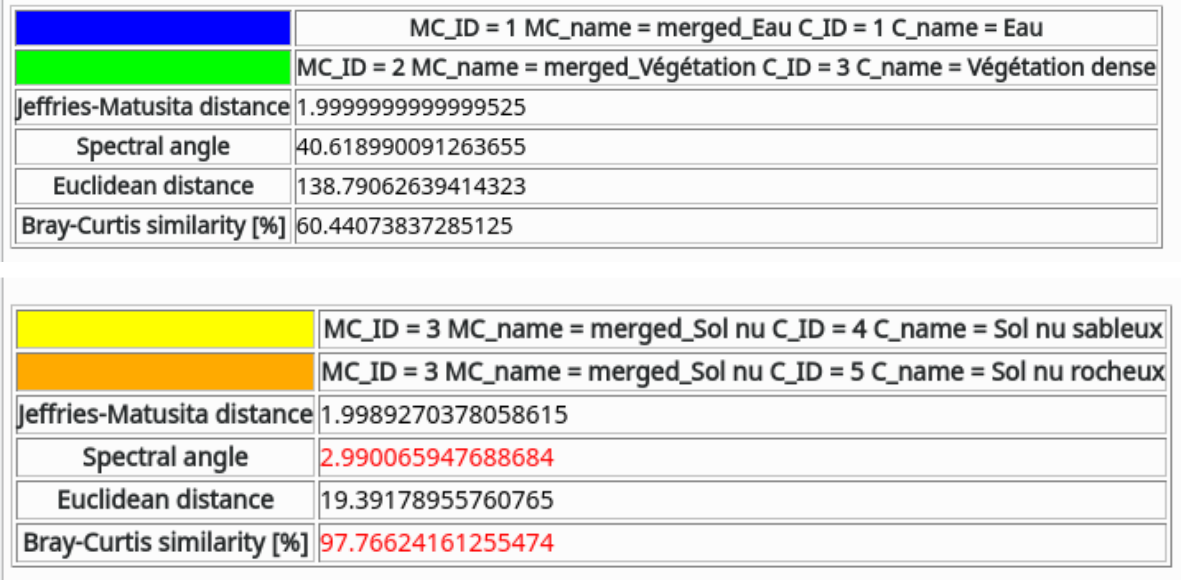
Fig. 392 Distances spectrales entre la classe Eau et Végétation dense (en haut) ; entre la classe Sol nu sableux et Sol nu rocheux (en bas).
Par exemple, les classes Eau et Végétation dense sont bien séparées. Par contre, les deux classes de sol nu sont très semblables. Elles seront donc probablement confondues lors du processus de classification.
Classification standard
Une fois satisfaits de nos polygones d’apprentissage, nous pouvons lancer le processus de classification proprement dit. Pour cela nous allons dans le menu . Le menu suivant apparaît (Fig. 393).
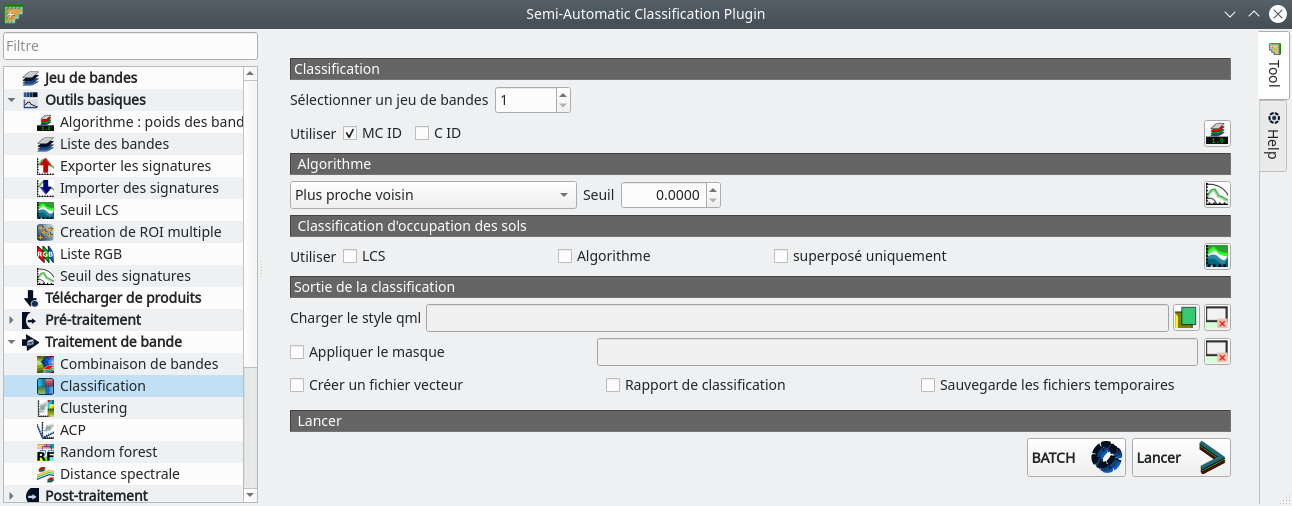
Fig. 393 Paramétrage de la classification.
Dans le panneau Classification nous spécifions le jeu de bandes à classifier, ici le 1. Nous indiquons si nous souhaitons effectuer la classification sur les méta-classes seulement ou sur les classes. Nous testerons les deux. Dans le panneau Algorithme nous choisissons un algorithme de classification. Le Plus proche voisin est couramment employé. Les autres paramètres peuvent conserver leurs valeurs par défaut. Le processus se lance en cliquant sur Lancer. Il faut spécifier un chemin et un nom pour le raster de classification qui sera créé. Nous pouvons noter que le raster produit respecte la symbologie définie par l’utilisateur au moment de la création des ROI (Fig. 394). Un fichier de style .qml accompagne le raster créé.
Astuce
Avant de lancer la classification sur toute l’image, il est possible de créer des aperçus sur différentes sous parties de l’image. Il suffit d’utiliser l’outil Activate classification preview pointer  de la
de la SCP Working Toolbar. Une fois l’outil sélectionné, le curseur se change en croix et un aperçu de classification se fait au moment du clic sur un carré de 200 pixels de côté. Le réglage de cette valeur est possible sur cette même barre d’outils. Il est possible d’enchaîner les aperçus, ce qui est pratique pour vérifier à priori le comportement de la classification sur les zones qui nous paraissent « compliquées ».
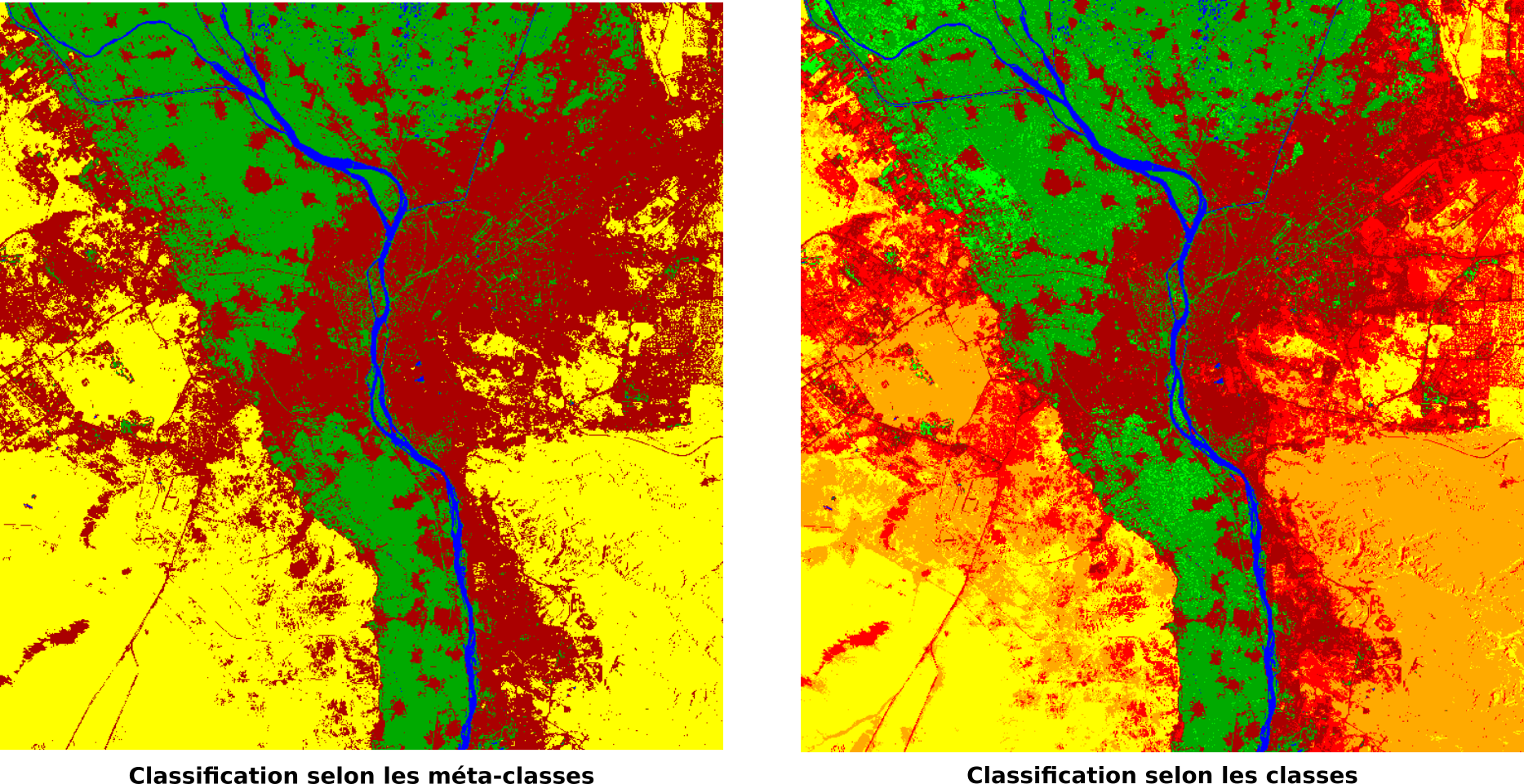
Fig. 394 Classification en méta-classe (gauche) et en classes (droite).
Comme vu au moment du calcul des distances spectrales, les classes de sol nu sont probablement en partie confondues et la classe d’urbain diffus est plus importante qu’en réalité. Elle déborde sur le Sol nu sableux. La figure suivante compare la même classification mais effectuée selon les trois algorithmes proposés. Celui utilisant le Spectral Angle Mapping semble moins faire déborder l’urbain diffus sur le sol nu sableux, alors que le Maximum de Vraisemblance, au contraire, le fait déborder encore plus (Fig. 395).
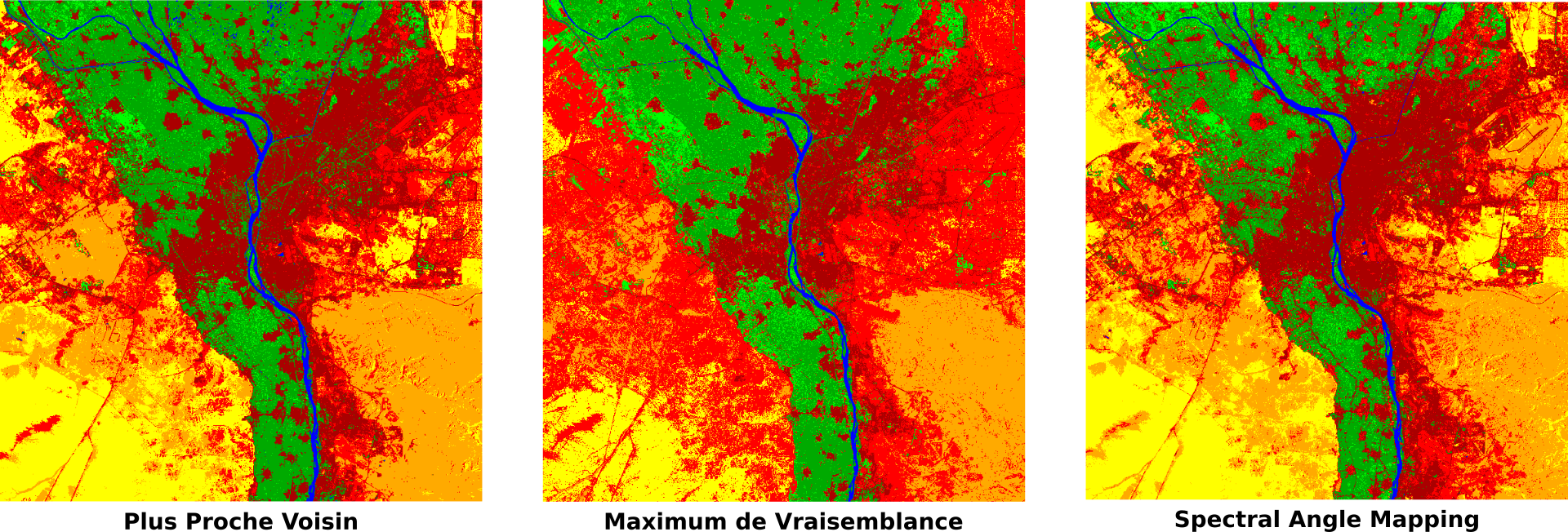
Fig. 395 Paramétrage de la classification.
C’est ensuite à l’utilisateur de tenter d’améliorer la classification en incluant plus de polygones d’apprentissage, notamment dans les zones qui semblent conflictuelles. Ou au contraire, en dégradant la classification en supprimant certaines classes qui seraient trop compliquées à individualiser.
Classification supervisée d’images satellites avec OTB
Version de OTB : 9.0.0
Orfeo ToolBox (OTB Orfeo ToolBox) propose des outils pour effectuer des classifications supervisées d’images satellites. La procédure avec OTB se passe en deux temps, d’abord une phase d’apprentissage basée sur des régions d’intérêts puis une phase d’application du modèle. Ces deux temps s’effectuent avec deux modules différents : trainImagesClassifier et ImageClassifier.
Dans cette section, nous prendrons le même exemple que pour la classification supervisée avec SCP, à savoir classifier une image Landsat TM du Caire prise le 13 juillet 2011. Seules les bandes 1 à 5 seront employées. Concrètement nous travaillerons sur un raster multi-bandes (Raster multi-bandes en dur (natif)) contenant les bandes 1 à 5. Nous ferons une classification en 7 classes comme expliqué précédemment : Définition des classes.
Couches d’apprentissage et de validation
Le première étape est de digitaliser une couche d’apprentissage de type polygones ainsi qu’une couche de validation de type polygones également. Les procédures de création de ces deux couches sont décrites dans les sections consacrées : Création des couches d’entraînement et de validation et Couche de validation.
Échantillonnage de la couche d’apprentissage
Orfeo ToolBox propose un ensemble de prétraitements qui permettent de définir finement la stratégie d’échantillonnage pour l’apprentissage. Concrètement, pour certaines classes les polygones d’apprentissage sont grands et contiennent donc beaucoup de pixels et d’autres classes sont représentées par de petits polygones contenant peu de pixels. Le déséquilibre des pixels d’apprentissage selon les classes peut avoir des répercussions sur le résultat final de la classification. OTB propose donc différentes techniques pour prendre en compte ce phénomène : prendre tous les pixels possibles, prendre le même nombre de pixels pour chaque classe, prendre une certaine proportion de pixels … Ces prétraitements ont également l’avantage d’extraire dans une table les signatures radiométriques de chaque échantillon d’apprentissage.
Avertissement
Cette phase de prétraitements n’est pas obligatoire, si vous êtes pressés, allez directement à la partie consacrée à l’apprentissage du modèle de classification : Apprentissage du modèle.
Statistiques par polygone
La première étape est de compter le nombre de pixels que représentent l’ensemble des polygones d’apprentissage pour chaque classe. Le module dédié se nomme PolygonClassStatistics ( (Fig. 396).
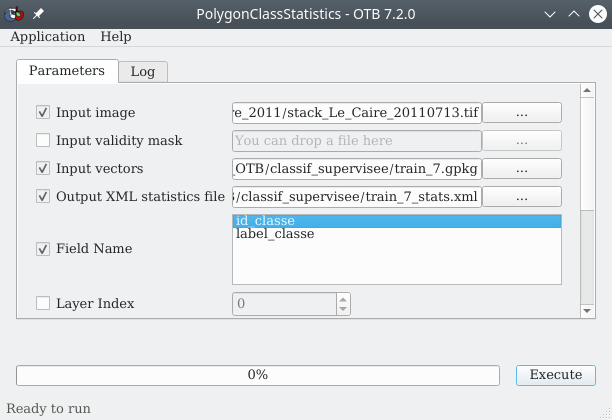
Fig. 396 Calcul des statistiques des polygones d’apprentissage.
Note
La couche d’apprentissage ne doit pas forcément être de type polygones, elle peut être de type points ou lignes.
À la ligne Input image nous sélectionnons le raster à classifier, ici le raster multi-bandes contenant les 5 bandes spectrales Landsat à utiliser pour la classification stack_Le_Caire_20110713.tif. À la ligne Input vectors nous renseignons la couche vecteur d’apprentissage train_7.gpkg. Dans le panneau Field Name, nous sélectionnons le nom du champ qui contient les identifiants numériques des classes id_classe. À la ligne Output XML statistics file nous indiquons un chemin et un nom pour le fichier XML qui contiendra les statistiques, nous pouvons le nommer train_7_stats.xml, puis nous cliquons sur Exécuter.
Avertissement
Il est nécessaire de préciser l’extension .xml dans le nom du fichier XML qui sera produit.
Astuce
Il est possible d’indiquer un masque pour cacher les portions du raster à ne pas prendre en compte, à la ligne Input validity mask.
Nous disposons maintenant d’un fichier XML contenant les statistiques du nombre de pixels disponibles pour l’apprentissage et pour chaque classe. Nous pouvons l’ouvrir avec un éditeur de texte (Fig. 397).
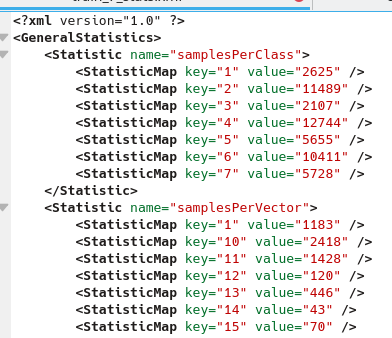
Fig. 397 Statistiques des polygones d’apprentissage.
Ce fichier renseigne sur le nombre de pixels que représentent chaque polygone d’apprentissage. Par exemple, pour la classe 1 (Eau) l’ensemble des polygones d’apprentissage représentent 2625 pixels. Cela signifie que l’apprentissage de l’eau peut se faire sur 2625 pixels au maximum. Par contre, les polygones d’apprentissage de la classe 2 (Végétation inondée) représentent 11489 pixels, ce qui est beaucoup plus. C’est ce déséquilibre que se propose de traiter l’ensemble de ces prétraitements.
La seconde partie du fichier XML renseigne sur le nombre de pixels de chaque polygone individuellement. Nous retrouvons bien 35 lignes, une par polygone d’apprentissage. Par exemple le polygone key= »10 » est constitué de 2418 pixels alors que celui key= »14 » n’est constitué que de 43 pixels.
Sélection des échantillons d’apprentissage
Maintenant que nous connaissons le nombre de pixels d’apprentissage disponibles pour chaque classe, nous pouvons adopter une stratégie de sélection de ces échantillons afin de rétablir (ou non) l’équilibre entre les classes. Le module dédié se nomme sampleSelection (Fig. 398). Six différentes stratégies d’échantillonnage sont proposées :
Constant strategy : toutes les classes seront échantillonnées avec le même nombre d’échantillons (i.e. de pixels), défini par l’utilisateur.
Smallest class strategy : la classe avec le moins de pixels disponibles sera totalement échantillonnée (tous ces pixels seront pris en compte) et ce même nombre de pixels sera adopté pour échantillonner toutes les autres classes.
Percent strategy : toutes les classes seront échantillonnées selon un même pourcentage de pixels défini par l’utilisateur.
Total strategy : un nombre total de pixels sera défini par l’utilisateur puis distribué proportionnellement entre toutes les classes.
Take all strategy : tous les pixels sont sélectionnés pour toutes les classes.
By class strategy : chaque classe est échantillonnée selon un nombre fixé par l’utilisateur (défini dans un fichier csv annexe).
De plus, dans chacun des polygones, il est possible de régler la stratégie d’échantillonnage spatial. Si seulement 10 % des pixels sont échantillonnés pour un polygone, il est possible de spécifier comment choisir ces 10 %. Les deux stratégies d’échantillonnage spatial sont :
Random : les pixels sont sélectionnés aléatoirement au sein des polygones.
Periodic : les pixels sont sélectionnés de façon régulière.
La stratégie d’échantillonnage se règle via le module sampleSelection qui se trouve dans la ( (Fig. 398).

Fig. 398 Stratégie d’échantillonnage des pixels d’apprentissage.
À la ligne InputImage, nous indiquons le raster multi-bandes qui servira à la classification. Il s’agît du raster à classifier stack_Le_Caire_20110713.tif. À la ligne Input vectors, nous indiquons le fichier vecteur de polygones d’apprentissage train_7.gpkg. À la ligne Input Statistics nous renseignons le fichier de statistiques que nous avons dérivé à l’étape précédente (Statistiques par polygone). Dans le panneau Sampler type nous choisissons une stratégie d’échantillonnage spatial parmi les deux proposées (periodic ou random), pour l’exemple nous prenons le periodic. Dans le panneau Sampling strategy nous choisissons une stratégie d’échantillonnage parmi les six décrites précédemment. Ici, pour l’exemple nous choisissons la Take all strategy (all). Enfin, dans le panneau Field name, nous indiquons le nom du champ qui contient l’identifiant numérique des classes id_classe. À la ligne Output vectors nous indiquons un chemin et un nom pour le fichier vecteur qui contiendra le résultat de l’échantillonnage, nous pouvons le nommer train_7_samples.gpkg. Nous pouvons sortir un fichier csv à la ligne suivante de façon facultative si nous souhaitons regarder en détails la stratégie d’échantillonnage employée. Puis nous cliquons sur Exécuter.
Avertissement
Il est nécessaire de préciser l’extension .gpkg (ou .shp) dans le nom du fichier vecteur qui sera produit à la ligne Output vectors.
Nous disposons maintenant d’une nouvelle couche vecteur de type Points nommée train_7_samples.gpkg. Nous pouvons ouvrir cette couche dans QGIS afin de voir à quoi elle correspond concrètement. Si nous zoomons sur un groupe de points nous constatons bien que ce groupe de points correspond à un polygone d’apprentissage (Fig. 399).
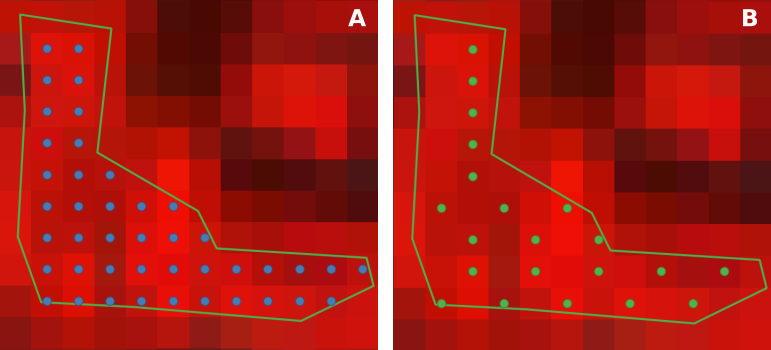
Fig. 399 Comparaison de deux stratégies d’échantillonnage : Take all strategy (A) et Percent strategy avec pourcentage fixé à 50 % et un échantillonnage spatial réglé à Periodic (B).
Sur la figure précédente (Fig. 399), la figure A présente le résultat de la stratégie que nous avons détaillée plus haut. Nous pouvons la comparer à la figure B qui correspond à une stratégie où nous aurions choisi de ne prendre que 50 % des pixels de chaque polygone et de les sélectionner de façon à n’en prendre qu’un sur deux.
Récupération des valeurs associées aux échantillons
L’ultime étape de ce prétraitement est d’associer pour les pixels d’échantillons sélectionnés les valeurs sous-jacentes du raster à classifier. Cela se fait à l’aide du module sampleExtraction (Fig. 400). Ce menu se trouve dans la (. Cette étape est intéressante car elle va nous permettre de tracer les signatures radiométriques de chaque polygone d’apprentissage et les signatures radiométriques moyennes de chaque classe. Nous pourrons ainsi déjà nous rendre compte des classes susceptibles d’être confondues.
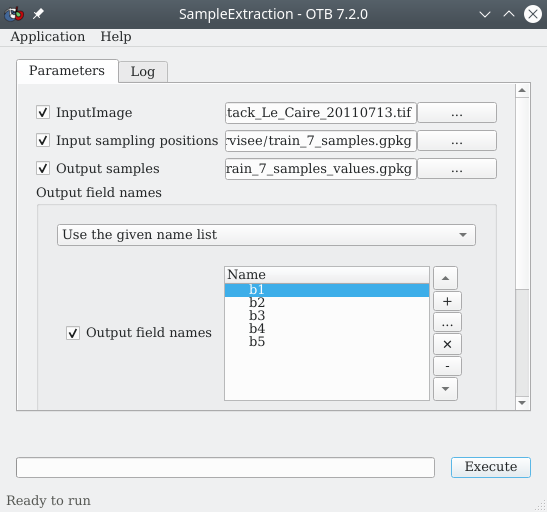
Fig. 400 Extraction des valeurs du raster à classifier au niveau des pixels échantillonnés.
À la ligne InputImage, nous indiquons le raster duquel nous souhaitons relever les valeurs, il s’agît du raster à classifier stack_Le_Caire_20110713.tif. À la ligne Input sampling positions nous pointons vers la couche vecteur de type points contenant les pixels à échantillonner telle que nous l’avons construite à l’étape précédente (Sélection des échantillons d’apprentissage). Dans le menu déroulant Output field names nous choisissons prefix, et à la ligne Output field prefix nous mettons b. Ainsi, les champs dans lesquels nous allons récupérer les valeurs de réflectances seront nommés b0, b1, jusqu’à la dernière bande du raster à classifier. À la ligne Field name nous indiquons le nom du champ qui contient l’identifiant numérique des classes dans la couche d’apprentissage id_classe. Enfin, à la ligne Output samples nous indiquons un chemin et un nom pour la couche vecteur de type points qui correspondra aux pixels échantillonnés auxquels les valeurs du raster sous-jacent auront été associées. Puis nous cliquons sur Exécuter.
Nous disposons maintenant d’une nouvelle couche de points qui est spatialement la même que celle définie à l’étape précédente (Sélection des échantillons d’apprentissage) mais qui contient dans sa table attributaire les valeurs du raster sous-jacent à classifier (Fig. 401).
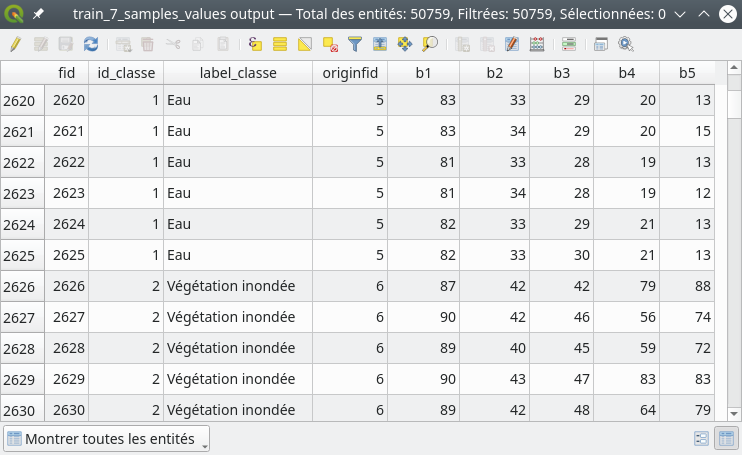
Fig. 401 Valeurs des bandes spectrales du raster à classifier sous-jacent aux pixels d’échantillons.
À chaque pixel est associé d’une part son identifiant de classe et son label de classe, et d’autre part les valeurs des bandes spectrales sous-jacentes. Par exemple, le pixel 15609 est labellisé comme étant de la végétation dense et présente des valeurs radiométriques de 0.097, 0.179, 0.375, 0.044, 0.045 et 0.028 respectivement dans les bandes 1 à 6, soient les bandes Bleu à Moyen infrarouge 2, codées ici de b0 à b5.
Note
Le nom des champs reprend l’ordre des couches du raster à classifier. L’utilisateur doit donc bien avoir en tête les correspondances de bandes.
À partir de cette couche il est possible de tracer les signatures radiométriques de chaque polygone ou de chaque classe en exportant la table dans un tableur ou via l’extension Data Plotly de QGIS (Fig. 402).
Note
La couche finale des points correspondant aux pixels des échantillons associées aux valeurs du raster à classifier sera la couche à employer dans la phase d’apprentissage qui vient juste après.
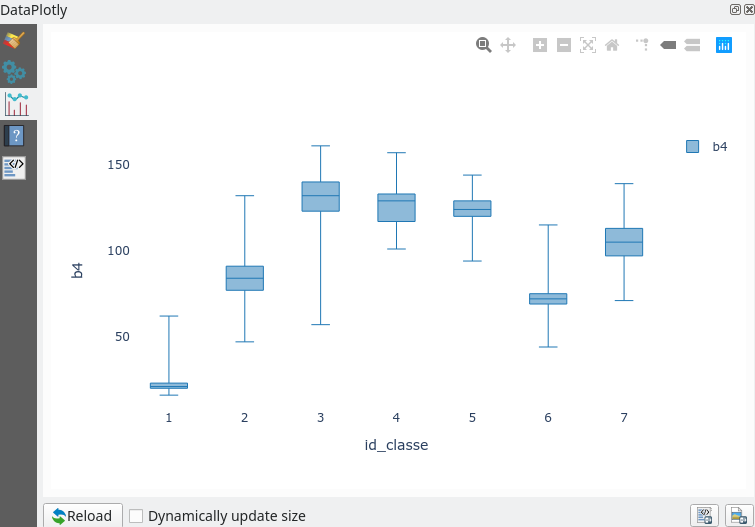
Fig. 402 Boîtes à moustaches des signatures dans la bande proche infrarouge des échantillons des 7 classes.
Apprentissage du modèle
L’étape suivante est de « faire apprendre » à un modèle à reconnaître les classes identifiées à partir des bandes spectrales, i.e. du raster multi-bandes, à classifier. Pour chaque classe, l’algorithme va extraire une sorte de signature radiométrique moyenne et va apprendre à la reconnaître. Cet apprentissage pourra reposer sur des algorithmes différents comme le Random Forest, le Support Vector Machine, le Boost Classifier … Les fondements théoriques de ces techniques ne seront pas discutés ici.
Pour cet apprentissage nous utilisons le module TrainImagesClassifier de OTB. Ce module se trouve dans la . La fenêtre suivante apparaît (Fig. 403).
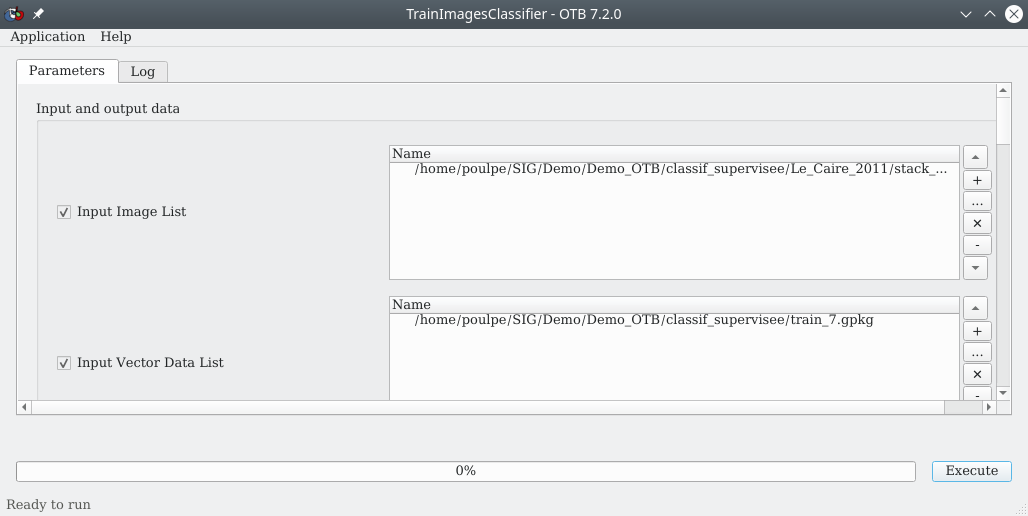
Fig. 403 Paramétrage de la phase d’apprentissage dans OTB.
Dans le panneau Input Image List nous renseignons le raster multi-bandes sur lequel l’algorithme devra apprendre. Ici, il s’agît de notre raster multi-bandes du Caire stack_Le_Caire_20110713.tif contenant les bandes TM 1 à 6. Dans le panneau Input Vector Data List, nous sélectionnons soit directement la couche vecteur qui contient les polygones d’apprentissage à savoir train_7.gpkg ou (encore mieux) la couche des points échantillonnés dans l’étape d’échantillonnage (Échantillonnage de la couche d’apprentissage). Nous pourrions cocher la case Validation Vector Data List et nous y pointer la couche vecteur de validation valid_7.gpkg. L’activation de cette option nous permettrait de « valider » notre classification c’est-à-dire calculer une matrice de confusion qui nous renseignerait sur la qualité de la classification. Mais un autre module de OTB dédié au calcul d’une matrice de confusion sera plus appropriée. À la ligne Output Model, nous indiquons un chemin vers lequel le fichier de modèle sera stocké. Ce fichier sera un simple fichier texte intelligible par OTB. Nous pouvons le nommer model_7_RF.txt. À la ligne Field containing the class integer label for supervision nous renseignons le champ de la couche vecteur d’apprentissage qui contient les identifiants numériques des classes, ici id_classe.
Avertissement
OTB ne travaille qu’avec des rasters multi-bandes en « dur » au format .tif. OTB ne prend pas en entrée les rasters virtuels .vrt.
Enfin, dans le panneau Classifier to use for the training, nous devons choisir un algorithme de classification. Plusieurs choix sont possibles, ici nous pouvons prendre par exemple le Random forests classifier (rf). Les autres paramètres peuvent conserver leurs valeurs par défaut. Nous cliquons pour finir sur Execute.
À l’issue de cette étape, la classification n’est pas encore effectuée, mais un fichier texte a été créé : un modèle, que nous avons nommé model_7_RF.txt. Le fichier de modèle est éditable avec un éditeur texte mais il ne sera pas intelligible pour nous. C’est ce fichier texte de modèle que nous utiliserons dans la seconde étape pour classifier notre image.
Application du modèle
La phase d’application se fait à l’aide du module ImageClassifier disponible dans la . La fenêtre suivante apparaît (Fig. 404).
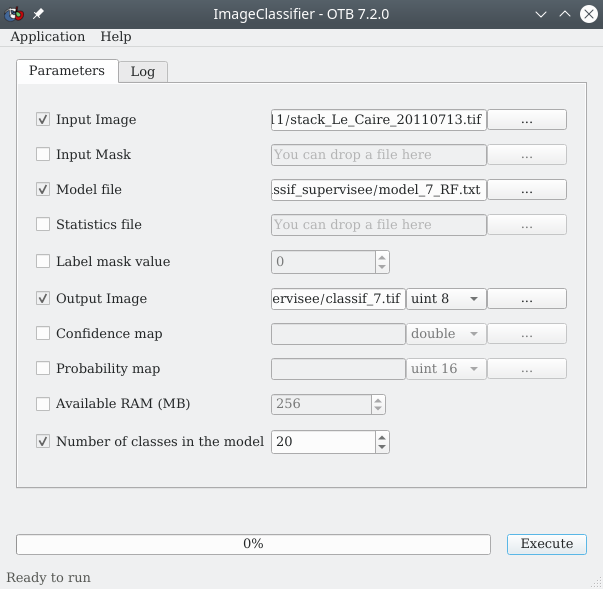
Fig. 404 Paramétrage de classification dans OTB.
À la ligne Input image list nous indiquons le raster multi-bandes à classifier, ici stack_Le_Caire_20110713.tif. À la ligne Model file, nous indiquons le fichier texte de modèle à utiliser pour la classification. Il s’agît du fichier de modèle créé à l’étape précédente d’apprentissage, ici model_7_RF.txt. Nous renseignons le chemin et le nom que prendra la classification à la ligne Output Image, nous pouvons la nommer classif_7.tif. Les autres options peuvent conserver leurs valeurs par défaut. Nous cliquons finalement sur Execute.
Astuce
Nous pouvons appliquer la classification seulement sur une portion de l’image si nous disposons d’un raster de masque. Un tel raster de masque doit avoir des valeurs positives sur les régions à classifier et négatives sur les régions à ignorer. Si nous disposons d’un tel masque nous le renseignons à la ligne Input Mask.
Nous obtenons un raster au format .tif présentant notre classification en 7 classes (Fig. 405).
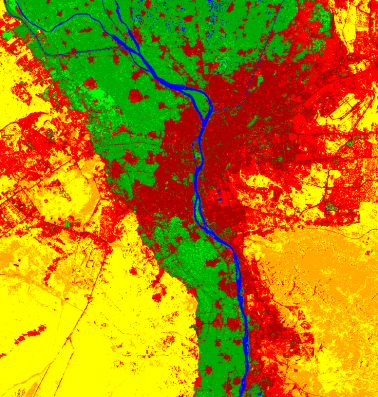
Fig. 405 Classification de l’image du Caire en 7 classes par Random Forest.