Auteur : Paul Passy
Licence : 
Post-traitement d’une classification
Une fois qu’une classification supervisée ou non a été faite, il est souvent nécessaire d’y appliquer un ou plusieurs post-traitements. Dans le cas d’une classification supervisée, il est notamment nécessaire d’en faire une évaluation, appelée validation.
Table des matières
Validation d’une classification supervisée
Après avoir effectué une classification supervisée d’images satellites, il est nécessaire de la valider. Une validation est en fait le calcul d’un ensemble d’indicateurs qui nous permettent d’apprécier quantitativement la justesse de notre classification. Un processus de validation fournit en premier lieu une matrice de confusion qui nous indique la qualité de la classification classe par classe. En second lieu, nous pouvons tirer de cette matrice de confusion des indicateurs globaux renseignant sur la qualité de la classification dans son ensemble.
Concrètement, une validation de classification résulte de la comparaison entre le raster de classification et des polygones de contrôle digitalisés manuellement par l’utilisateur (Couche de validation). Cette comparaison peut se faire à l’aide de différents outils dont certains sont présentés ici.
Dans ces exemples d’application, nous allons valider une classification de l’occupation du sol de la région du Caire en Égypte à partir d’une image Landsat 5 TM du 13 juillet 2011. Cette classification a été mise en œuvre dans la partie dédiée aux classifications.
Note
Avec certains outils il est possible de faire la validation directement au moment de la classification. Ici, nous verrons seulement les outils qui proposent de faire la validation à postériori.
Pour rappel, la classification du Caire que nous souhaitons valider dans cet exemple est un usage du sol en sept classes comme présentées dans le tableau suivant.
ID classe |
Label classe |
|---|---|
1 |
Eau |
2 |
Végétation inondée |
3 |
Végétation dense |
4 |
Sol nu sableux |
5 |
Sol nu rocheux |
6 |
Bâti dense |
7 |
Bâti diffus |
Validation avec le plugin SCP de QGIS
Version de QGIS : 3.18.1
Version de SCP : 7.8.7
Lancement
Le plugin SCP de QGIS permet de faire des classifications supervisées ou non supervisées et propose également un grand panel d’outils tournant autour de ces questions de classifications. L’un de ces outils est justement un outil de post-traitement permettant de calculer une matrice de confusion et des indicateurs quantitatifs relatifs à la qualité d’une classification supervisée. Pour utiliser cet outil, il est nécessaire de disposer d’un raster de classification et de polygones de contrôle, c’est-à-dire d’une couche de validation. Cette couche de validation s’obtient par digitalisation manuelle de polygones de contrôle (Couche de validation).
Astuce
Le raster de classification peut bien sûr être issu d’une classification effectuée à l’aide du plugin SCP, mais peut également avoir été produit avec tout autre outil.
L’outil de validation se trouve dans le menu . Le menu suivant s’affiche (Fig. 406).
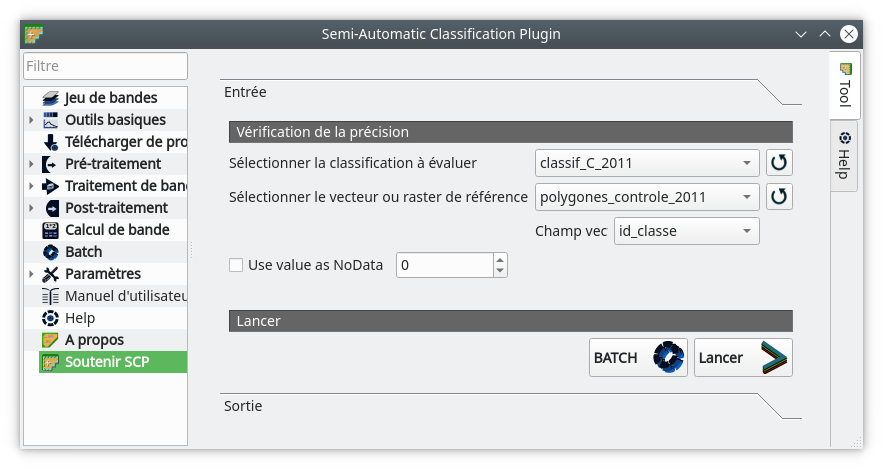
Fig. 406 Paramètres de la validation.
Dans le champ Sélectionner la classification à évaluer, nous sélectionnons le raster à évaluer. Si il n’apparaît pas dans le menu déroulant, il peut être nécessaire de rafraîchir cette liste en cliquant sur l’icône Actualiser la liste  . Ensuite, dans le champ
. Ensuite, dans le champ Sélectionner le vecteur ou raster de référence, nous choisissons le fichier de polygones de contrôle. Enfin, dans le champ Champ vec, nous indiquons le champ de la couche vecteur qui contient les identifiants numériques de classe. Bien sûr ces identifiants doivent être identiques à ceux du raster de classification. Ensuite, nous lançons la validation en cliquant sur Lancer.
Les polygones de contrôle vont être rasterisés afin d’être comparés à la classification. Le module nous demande de sauver cette rasterisation à un endroit de notre choix. Nous pouvons la nommer valid_2011.tif.
Lecture
Deux sorties ont été produites : un raster et un fichier texte au format .csv. C’est le fichier texte qui va nous intéresser. Ce texte est également reproduit dans le panneau Sortie de la fenêtre de validation de SCP (Fig. 407).
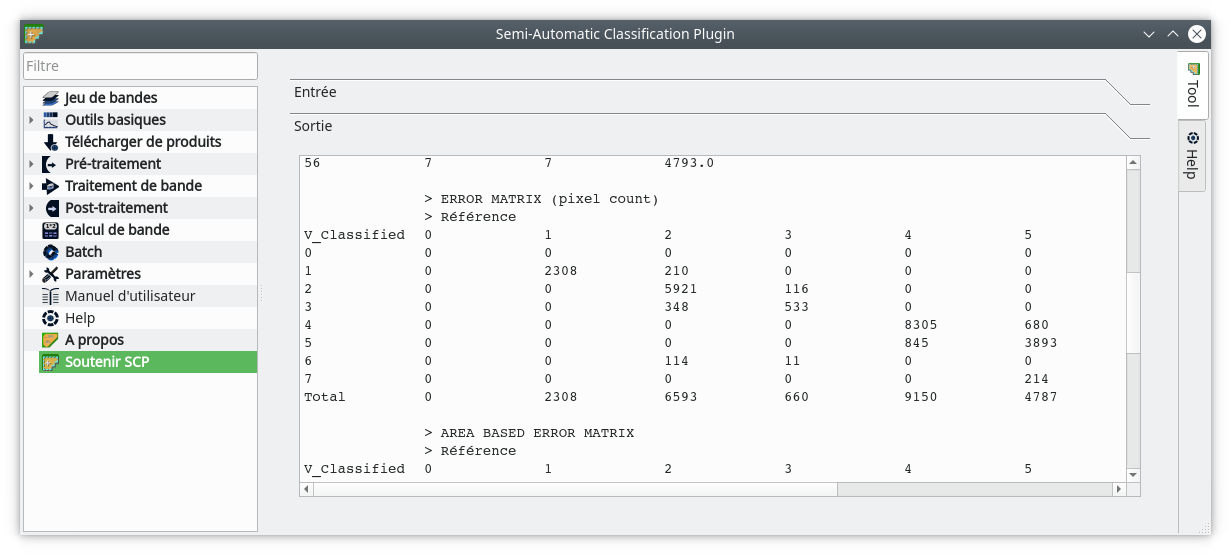
Fig. 407 Sortie texte de la validation par SCP.
Le raster est à mettre en parallèle du premier bloc du fichier texte selon la figure suivante (Fig. 408). Sur cette figure, nous prenons d’abord l’exemple de pixels du raster de validation présentant la valeur 2 (en bleu). La signification de cette valeur se trouve dans le premier bloc de texte du fichier csv. La valeur 2 correspond ainsi aux pixels étant identifiés en référence comme appartenant à la classe 1 (eau). C’est-à-dire que ces pixels appartiennent à des polygones de contrôle identifiés comme étant de la classe 1. Mais ces pixels correspondent également à des pixels classifiés en classe 1. C’est-à-dire que ces pixels sont en 1 sur le raster de classification. Au final, ce sont donc des pixels classifiés en 1 et identifiés en contrôle en 1 également. Il s’agît donc de pixels d’eau bien classés. Nous pouvons en plus lire sur le fichier texte qu’en tout, 2308 pixels appartiennent à cette catégorie. Il y 2308 pixels classifiés en eau et dont le contrôle nous dit bien qu’il s’agît d’eau.
Par contre, les pixels en vert sont des pixels labellisés 37. Cette valeur de 37 correspond aux pixels qui appartiennent à des polygones de contrôle de Sol nu rocheux (classe 5) mais qui ont été classifiés en Sol nu sableux (classe 4). Il s’agît donc des pixels confondus entre les deux classes de sol nu. En tout, 680 pixels, parmi les pixels de contrôle, présentent cette confusion.
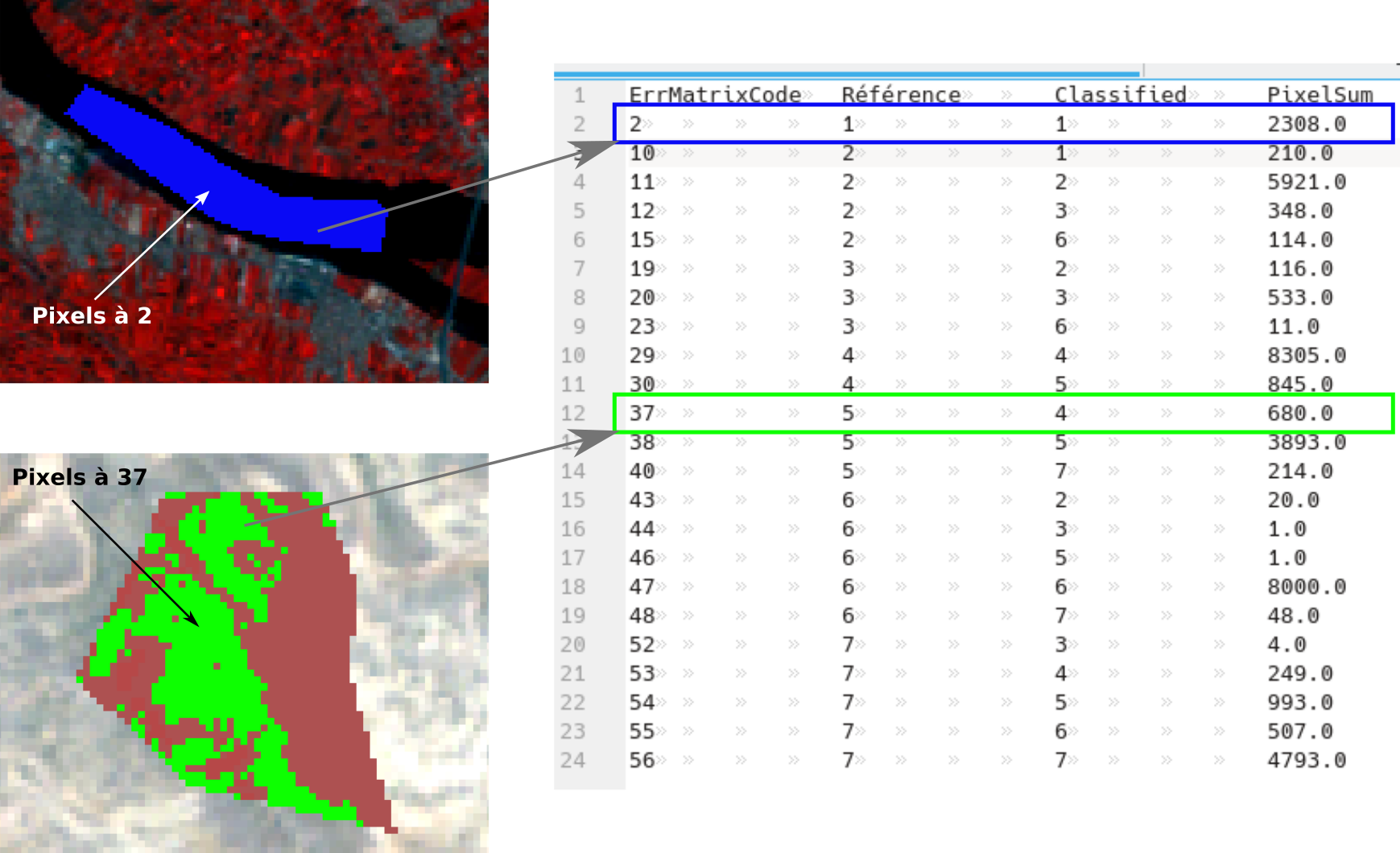
Fig. 408 Raster de validation produit par SCP.
Ce raster de validation est un sous produit intéressant pour visualiser finement dans l’espace les zones qui posent problème. Ce raster peut aider l’utilisateur à revoir ces zones d’entraînement en y incluant éventuellement des polygones représentatifs des problèmes.
Le deuxième bloc du fichier texte correspond à la matrice de confusion, appelée ici matrice d’erreur (Fig. 409).
Fig. 409 Matrice d’erreur en compte de pixels.
Dans cette matrice, en ligne nous retrouvons les 7 classes d’occupation du sol de nos polygones de validation, i.e. la vérité terrain (> Référence). En colonne, nous retrouvons ces 7 mêmes classes d’occupation du sol mais telles que classifiées (V_Classified). La classe 0 correspond aux pixels non classifiés, ici les bords de l’image, nous pouvons en faire abstraction.
À chaque intersection de lignes et de colonnes, nous retrouvons un nombre (un compte) de pixels. Par exemple, parmi nos polygones de contrôle, 2308 pixels ont été identifiés comme de la classe 1 (eau) et en même temps classifiés comme étant de la classe 1. La diagonale correspond ainsi au nombre de pixels correctement classés pour chaque classe.
La colonne Total correspond au nombre total de pixels de chaque classe recouverts par nos polygones de validation. Ainsi, nos polygones de validation recouvrent 2518 pixels de notre raster de classification classés en eau (classe 1). De même, nos polygones de validation recouvrent 5055 pixels de bâti diffus (classe 7) sur notre raster de classification.
La ligne Total correspond au nombre total de pixels recouverts pour chaque classe de polygone de validation. Par exemple, les polygones de validation identifiés comme étant de l’eau (classe 1) recouvrent 2308 pixels du raster de classification. Dans la même idée, les polygones de validation identifiés comme étant du bâti diffus (classe 7) recouvrent 6546 pixels du raster de classification.
Grâce à ces éléments, nous pouvons calculer les deux indicateurs suivants : la qualité producteur (Qualité producteur et erreur par omission) et la qualité utilisateur (Qualité utilisateur et Erreur par commission).
Le bloc suivant du fichier texte intitulé Area Based Error Matrix reprend cette matrice de confusion mais exprimée en aires non biaisées. Nous ne la détaillerons pas ici.
Enfin, les lignes Précision globale et Kappa hat classification présentent des statistiques de qualité globale. La précision globale doit tendre vers 100 % et le Kappa hat classification doit tendre vers 1.
Note
Au final, SCP propose un outil plutôt puissant pour évaluer la qualité d’une classification supervisée. Le raster de validation est particulièrement intéressant pour visualiser les pixels non correctement classés. Les matrices de confusion calculées présentent tous les éléments nécessaires à l’évaluation de la classification. Cependant, une documentation pour bien comprendre toutes les sorties serait la bienvenue.
Validation avec Orfeo ToolBox
Version de OTB : 9.0.0
OTB propose un module dédié au calcul d’une matrice de confusion suite à une classification supervisée. En entrée, il est logiquement nécessaire de disposer d’un raster de classification d’occupation du sol (construit avec OTB ou un autre outil) et de polygones de validation. OTB va confronter ces deux données pour calculer une matrice de confusion qui renseignera sur la qualité de la classification. Comme tout module OTB, il est utilisable via QGIS ou via la ligne de commande otbcli dédiée.
Avec OTB via QGIS
Le module dédié se trouve dans la . Le menu suivant s’ouvre (Fig. 410).
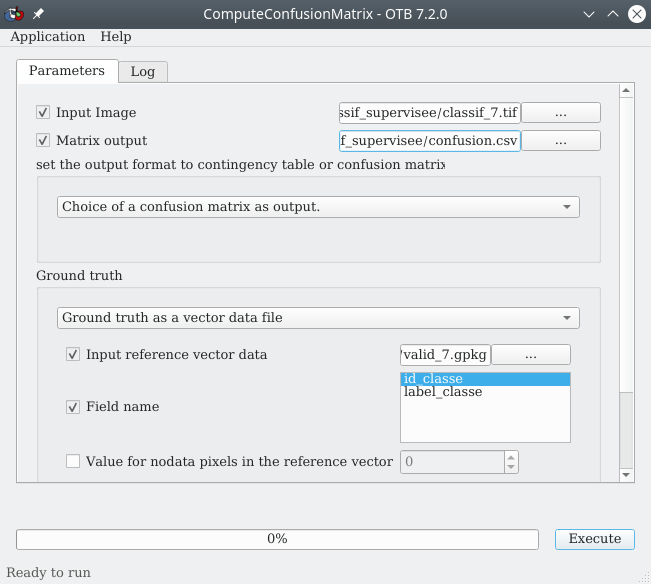
Fig. 410 Module de calcul de matrice de confusion dans OTB.
À la ligne Input image nous pointons vers le raster de classification à évaluer, ici classif_7.tif. Nous indiquons ensuite dans le menu déroulant que nous souhaitons sortir une matrice de confusion (confusionmatrix) et non pas une table de contingence. Puis, dans le panneau Ground truth nous allons renseigner la vérité terrain sous forme d’un fichier vecteur ou raster. Ici nous disposons de polygones de validation, donc d’un fichier vecteur. Nous sélectionnons donc vector dans le menu déroulant Ground truth. Ensuite nous pointons vers le fichier vecteur contenant les polygones de validation à la ligne Input reference vector data, ici valid_7.gpkg. Puis nous spécifions le Field name contenant l’identifiant des classes, id_classe. À la ligne Matrix output nous indiquons un chemin et un nom pour la matrice de confusion qui sera produite. Cette matrice sera sous forme d’un fichier texte. Nous pouvons la nommer confusion.csv. Il ne reste plus qu’à cliquer sur Exécuter.
Création via la ligne de commande
Cette manipulation peut se faire en utilisant la ligne de commande otbcli dédiée. Cette manipulation peut être pratique dans le cas d’une automatisation de processus. La ligne de commande à utiliser est la suivante :
otbcli_ComputeConfusionMatrix -in classif_7.tif -ref vector -ref.vector.in valid_7.gpkg -ref.vector.field id_classe -out confusion_matrix.csv
où :
otbcli_ComputeConfusionMatrix : l’appel au module
-in classif_7.tif : le raster de classification à évaluer
-ref vector : l’indication si la couche de validation est sous forme de raster ou de vecteur
-ref.vector.in valid_7.gpkg : le fichier de polygones vecteur à utiliser pour la validation (utiliser -ref.raster.in si la couche de validation est au format raster)
-ref.vector.field id_classe : l’indication du nom du champ qui contient les identifiants numériques des classes
-out confusion_matrix.csv : le nom de la matrice de confusion à produire
Après l’exécution de cette commande nous retrouvons bien notre matrice de confusion au format .csv.
Astuce
En utilisant ce module via la ligne de commande nous obtenons les indicateurs de qualité calculés en sortie sur la console.
Lecture
La matrice est créée sous forme de fichier texte. Le format n’est pas des plus commodes, il est nécessaire de le changer un peu avant d’interpréter la matrice. Nous pouvons commencer par ouvrir de fichier texte avec un éditeur de texte, mais la lisibilité est compliquée. Il est plus simple de l’ouvrir avec un tableur comme Excel ou LibreOffice Calc. Nous pouvons régler les séparateurs comme étant la « virgule » (,) et les deux points (:). Malgré ça, une fois le fichier ouvert, il faut encore décaler les colonnes de chiffres de une colonne vers la droite et copier - coller en transposé les chiffres de la première ligne d’en-tête, afin d’obtenir une matrice comme présentée ci-dessous (Fig. 411).
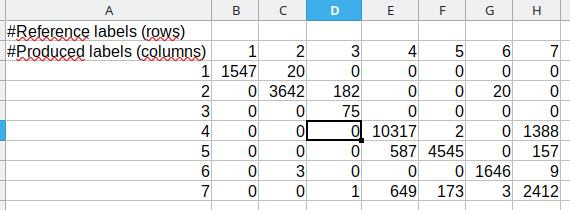
Fig. 411 Ouverture et réglage de la matrice de confusion OTB dans un tableur.
Comme souvent pour les matrices de confusion, les lignes correspondent aux classes de référence, c’est-à-dire aux classes de vérité terrain soit les classes de validation. Les colonnes, quant à elles, correspondent aux classes prédites i.e. les classes simulées ou classifiées. La grille de lecture est la même que pour une matrice de confusion créée avec le plugin SCP. Sur cet exemple, la valeur 1547 à l’intersection de la colonne 1 et de la ligne 1 signifie que 1547 pixels identifiés comme appartenant à la classe 1 en validation ont en effet été classifiés en classe 1 par notre classification. La classe 1 correspond ici à l’eau, donc 1547 pixels identifiés comme étant de l’eau en validation ont bien été classifiés en eau. Par contre, 20 pixels identifiés comme étant de la classe 1 (eau) en validation ont été classifiés comme appartenant à la classe 2 (végétation inondée). L’eau a donc tendance a être (légèrement) sous évaluée par rapport à la végétation inondée. Mais la confusion entre les deux classes n’est pas forcément surprenante, la végétation inondée contient par définition de l”eau.
Au contraire, la classe 4 - sol nu sableux - est largement confondu avec la classe 7 bâti diffus. En effet, 10317 pixels identifiés comme étant du sol nu sableux en validation sont bien classifiés en sol nu sableux mais 1388 de sol nu sableux ont été classifiés en bâti diffus . Là encore ce résultat était attendu, vu la difficulté de bien distinguer ces deux occupations du sol même visuellement sur l’image de départ.
Il est possible d’aller plus loin dans l’analyse de cette matrice en calculant les indicateurs quantitatifs renseignant sur la qualité globale de la classification ou sur la qualité classe par classe (Indicateurs de qualité). Pour cela, il est nécessaire d’ajouter une colonne de somme tout à droite et une ligne de somme tout en bas (somme en ligne et somme en colonne (Fig. 412).
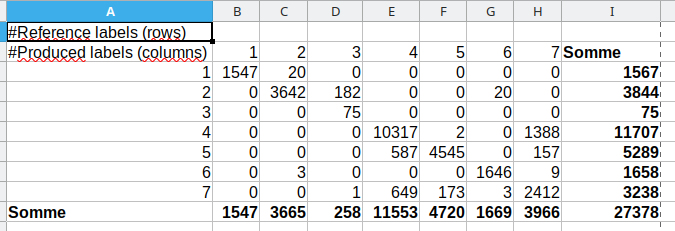
Fig. 412 Somme en ligne et en colonne d’une matrice de confusion calculée avec OTB.
Ces sommes se lisent comme suit. Par exemple, ici sur la ligne des sommes, 3665 pixels ont été classifiés en classe 2. Tandis que sur la colonne des sommes nous constatons que 3844 pixels ont été identifiés en validation comme appartenant à la classe 2.
Note
Au final, OTB propose un module basique de calcul de matrice de confusion. Il serait pratique que cette matrice soit exportée dans un format mieux structuré et que certains indicateurs globaux soient déjà calculés.
Indicateurs de qualité
À partir d’une matrice de confusion il est possible de calculer une batterie d’indicateurs quantitatifs renseignant sur la qualité d’une classification. Certains indicateurs renseignent sur la qualité de classification classe par classe et d’autres renseignent sur la qualité globale de la classification. Pour les exemples suivants, nous nous baserons sur la matrice de confusion suivante (Fig. 413).
Fig. 413 Matrice d’erreur en compte de pixels avec les sommes en lignes et colonnes.
Qualité utilisateur et Erreur par commission
La qualité utilisateur (user’s accuracy en anglais), aussi appelée précision utilisateur, s’obtient, pour chaque classe, en divisant le nombre de pixels correctement classés par le nombre total de pixels prédits dans cette classe. Cela revient à diviser le nombre de pixels bien classés (sur la diagonale) par le total en colonnes. Par exemple, ici, la qualité utilisateur de la classe Végétation inondée (classe 2) est de :
Cette qualité utilisateur revient à répondre à cette question : « Si je vais sur un endroit de ta carte qui a été classifié en 2, quelle est la probabilité que cet endroit soit réellement du 2 sur le terrain ? ».
À partir de qualité utilisateur il est possible de calculer une erreur par commission. Cette erreur par commission correspond à la proportion des pixels qui ont été incorrectement attribués à une classe particulière. Elle se calcule en retranchant la qualité utilisateur à 1.
Dans notre cas, pour la classe 2 :
Nous pouvons donc dire que notre classe 2 est surestimée de 0.63 %.
Qualité producteur et erreur par omission
La qualité producteur (producer’s accuracy en anglais), aussi appelé rappel produecteur, s’obtient, pour chaque classe, en divisant le nombre de pixels correctement classés par le nombre total de pixels utilisés en validation pour cette classe. Cela revient à diviser le nombre de pixels bien classés (sur la diagonale) par le total en lignes. Par exemple, ici, la qualité producteur de la classe Végétation inondée (classe 2) est de :
Cette qualité producteur revient à répondre à cette question : « Quelle est la probabilité qu’une zone réellement en 2 sur le terrain soit classifiée en 2 sur ta carte ? ».
À partir de qualité producteur il est possible de calculer une erreur par omission. Cette erreur par omission correspond à la proportion de pixels qui appartiennent réellement à une classe sur le terrain qui n’ont pas été classifiés dans cette classe. Elle se calcule en retranchant la qualité producteur à 1.
Dans notre cas, pour la classe 2 :
Nous pouvons donc dire que 5.25 % de nos pixels de classe 2 n’ont pas été détectés.
Précision globale
La précision globale (Overall accuracy en anglais) s’exprime en pourcentage et renseigne sur la qualité globale de la classification. Elle se calcule en divisant la somme des pixels bien classés par la somme totale des pixels. Par exemple, ici :
Indice Kappa
L’indice kappa (ϰ), calculé sur l’ensemble des classes, renseigne également sur la qualité globale de la classification. Son calcul prend en compte le fait que certains pixels peuvent être bien classés au hasard. Cet indice varie entre -∞ et 1. Plus le kappa se rapproche de 1 meilleure est la classification. Il est possible d’interpréter les valeurs de l’indice ϰ en suivant ce tableau.
Indice ϰ |
Interprétation |
|---|---|
< 0 |
Désaccord |
0 - 0.2 |
Accord très faible |
0.21 - 0.40 |
Accord faible |
0.41 - 0.60 |
Accord modéré |
0.61 - 0.80 |
Accord fort |
0.81 - 1.00 |
Accord presque parfait |
Avertissement
Les matrices de confusion et les indicateurs associés sont des outils indispensables à tout processus de classification. Toute classification doit être accompagnée d’une matrice de confusion commentée. Par contre, il faut garder en tête que la matrice de confusion est extrêmement dépendante des échantillons de classes digitalisés par l’utilisateur.
Fusion de classifications
Il existe de nombreuses méthodes de classifications supervisées d’images satellites, basées sur différents algorithmes comme le Random Forest, le Support Vector Machine, Normal Bayes Classifier, … De plus, chacune peut prendre en entrée des valeurs de paramètres définis par l’utilisateur. Par exemple, une classification en Random Forest prend en entrée un nombre d’arbres, une profondeur d’arbre maximale, … Au final, il n’est pas toujours facile de choisir un résultat de classification parmi d’autres. Une stratégie consiste à effectuer plusieurs classifications, soit en utilisant des algorithmes différents, soit en utilisant des paramètres d’entrée différents, puis de fusionner ces différents résultats de classification. L’idée est d’obtenir la classification qui résume le mieux les différents résultats. Il existe différentes façon d’effectuer ces fusions, selon les outils utilisés.
Fusion de classifications avec OTB
Version de OTB : 9.0.0
Le logiciel Orfeo ToolBox propose un outil pour fusionner plusieurs classifications, nommé FusionOfClassifications. Cet outil propose deux méthodes de fusion : Majority Voting et Dempster Shafer combination. Nous détaillerons ici la première méthode. Pour l’exemple, nous avons effectué 5 classifications supervisées d’une scène Landsat au-dessus de la ville du Caire, en Égypte. Ces classifications ont été faites avec 4 algorithmes différents et 2 configurations différentes pour la classification utilisant le Random Forest (Fig. 414).
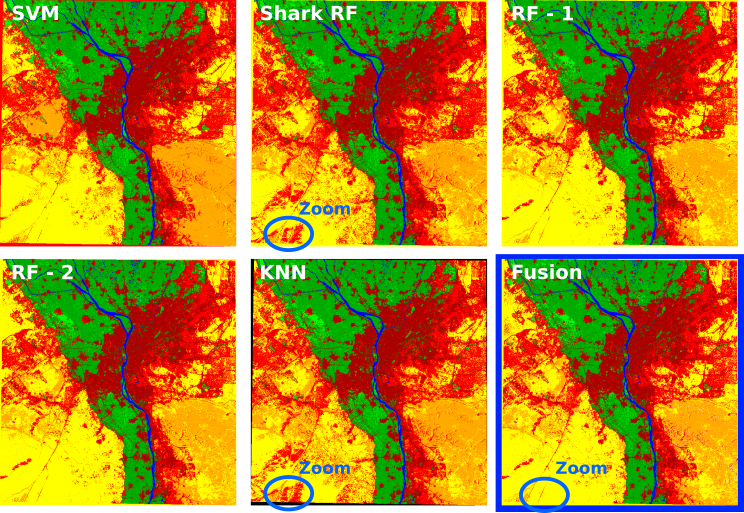
Fig. 414 Cinq classifications différentes et résultat de leur fusion (entourée en bleu).
Avec OTB via QGIS
Dans OTB avec QGIS, pour lancer le module de fusion, il suffit d’aller dans le menu . Le menu suivant s’ouvre (Fig. 415).
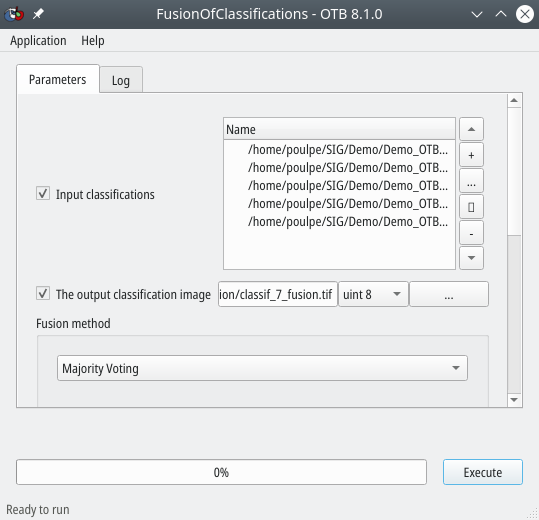
Fig. 415 Fusion de cinq classifications dans OTB.
Dans le panneau Input Classifications, nous indiquons les classifications à fusionner, à savoir nos cinq classifications. À la ligne The output classification image, nous indiquons le chemin et le nom du raster résultant à la fusion. Dans le menu déroulant Fusion method, nous choisissons la méthode de fusion à utiliser, ici Majority voting. Via cette méthode, dans le raster de fusion, à chaque pixel nous allons associer la valeur qui revient le plus souvent dans les classifications. Par exemple, dans la zone Zoom de la figure (Fig. 414), les pixels sont classés en Bâti diffus (en rouge clair) dans deux classifications et en Sol nu sableux (en jaune) dans trois classifications. Par conséquent, dans la fusion, cette zone sera classée en Sol nu sableux (3 occurrences VS 2 occurrences).
Cette méthode a une limite lorsque le choix ne peut pas être fait, c’est-à-dire quand il n’y a pas de classes majoritaires. Par exemple, sur un zoom de la fusion précédente, un tel problème apparaît (Fig. 416). Par défaut, une valeur sera attribuée à ces pixels sans décisions. Cette valeur est à O par défaut mais peut être changée à la ligne Label for the Undecided class.
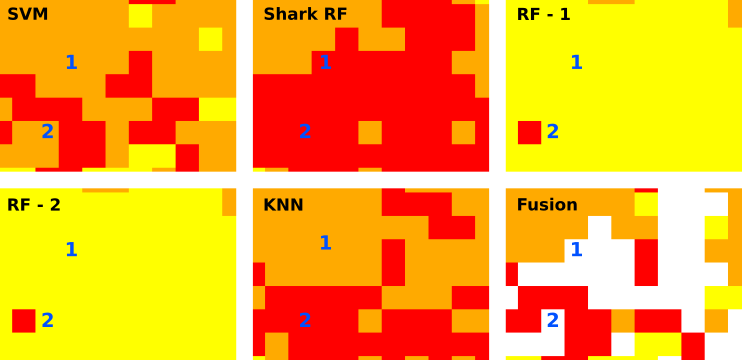
Fig. 416 Choix majoritaire impossible pour les pixels 1 et 2.
Sur la figure (Fig. 416), le pixel 1 apparaît une fois classifié en Bâti diffus (en rouge clair), deux fois en Sol nu rocheux (en orange) et deux fois en Sol nu sableux (en jaune). La fusion par Vote majoritaire ne peut donc pas faire de choix. Le pixel apparaît donc en 0 sur le raster de fusion final. Le même cas de figure existe pour le pixel 2. Le choix est impossible entre Bâti diffus (en rouge clair) et Sol nu sableux (en jaune). Si l’utilisateur le souhaite, il est possible de changer à posteriori ces valeurs en no data puis de les combler d’une façon ou d’une autre avec la classe majoritaire la plus proche par exemple.
La seconde méthode de fusion proposée Dempster Shafer combination est plus complexe et repose sur l’analyse des matrices de confusion de chacune des classifications à fusionner. Pour les détails de cette méthode, reportez vous à la page dédiée de la documentation du module FusionOfClassifications de OTB.
Avec la commande otbcli
En ligne de commande, l’opération est simple, il suffit de bien respecter la syntaxe et de bien se placer dans le répertoire qui contient nos classifications à fusionner. Nous commençons par appeler le module otbcli_FusionOfClassifications, nous définissons ensuite les classifications en entrée via le paramètre -il, puis nous définissons le nom du raster de fusion résultat via le paramètre -out. Enfin, nous choisissons la méthode de fusion via le paramètre -method. Dans notre cas, la ligne de commande est la suivante :
otbcli_FusionOfClassifications -il classif_7_RF.tif classif_7_RF-2.tif classif_7_Shark_RF.tif classif_7_SVM.tif classif_7_KNN.tif -method majorityvoting -out classification_fused.tif
L’avantage est qu’en ligne de commande, le processus tourne très vite.